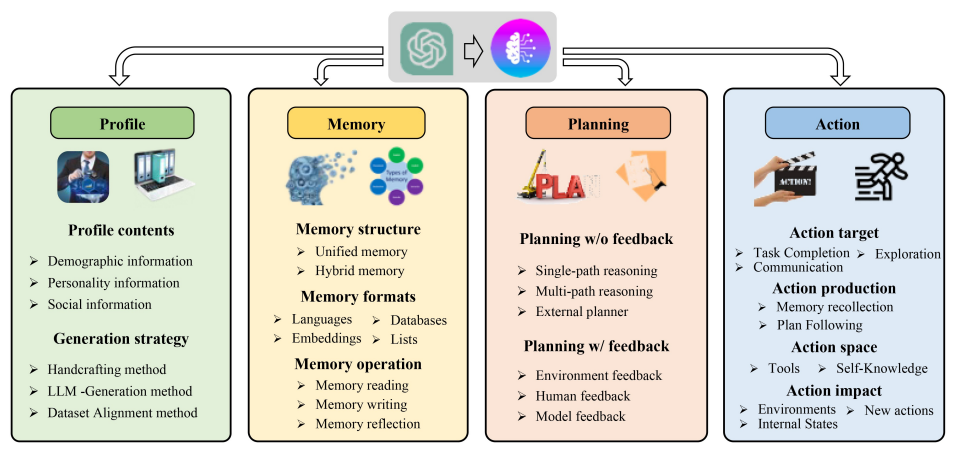
AIエージェントのセキュリティリスク概観
 この記事をシェアする
この記事をシェアする



はじめに
こんにちは、ARISE analytics(以下ARISE)の奥井 恒です。普段はセキュリティに関するAI技術の研究開発を担当しています。本記事ではAIエージェント利用に伴うリスクと対応策について解説します。 2025年はAIエージェントの年になると巷で話題になっており、ARISE含め多くの企業が開発や事業展開に取り組んでいます。 価値貢献のためにAIエージェントをいかに使用するか考えることも重要ですが、そのためにはAIエージェントを安全に使用できることが前提になると思います。そこで、今回は、AIエージェントを利用する際のセキュリティ課題について調べてみました。 具体的には、AIエージェントが直面するセキュリティ課題についてのサーベイ論文の内容を紹介します。
読んだ論文はこちらです。
AI Agents Under Threat: A Survey of Key Security Challenges and Future Pathways
この論文のサーベイ対象は、2022年1月から2024年4月までの期間に発表されたトップAI会議、主要なサイバーセキュリティ会議、引用回数の多いarXivの論文です。
本記事では、論文の内容に沿い、AI Agentのワークフローについて軽く解説した上で、一般的なAIエージェントのワークフローの各段階で採用される攻撃戦略を解説していきます。
なお、本記事で記載している論文の引用番号は、本記事が参照しているサーベイ論文の引用番号を用いて記載しています。詳細が気になる方は、お手数おかけしますが、サーベイ論文をご参照ください。
AI Agentのワークフロー
AIエージェントは、ユーザーのタスクを効率的に支援するために設計された計算エンティティです。AIエージェントの一般的なワークフローが以下の図で示されています。

今回は、AIエージェントのワークフローが、内部実行(Intra-execution)と相互作用(Interaction)の大きく2つのコアコンポーネントから成り立っているとします。
内部実行(Intra-extraction)
AIエージェントの内部実行は、知覚(Perception)、脳(Brain)、行動(Action)モジュールを含みます。知覚は脳に効果的な入力を提供し、行動はLLM(大規模言語モデル)の推論と計画能力を使ってこれらの入力をサブタスクとして処理します。そして、これらのサブタスクは行動によって順次実行され、ツールが呼び出されます。
相互作用(Interaction)
相互作用とは、AIエージェントが外部リソースを通じて他の外部エンティティと関与する能力を指します。これには、マルチエージェントアーキテクチャ内での協力や競争(Agent2Agent)、タスク実行中のメモリの取得(Agent2Memory)、外部ツールからの環境やデータの利用(Agent2Environment)が含まれます。なお今回は論文に従い、メモリは外部リソースとして定義しています。なぜなら、メモリに関連するセキュリティリスクの多くは外部リソースの取得から生じるためです。
今回はAIエージェントのセキュリティが本題なので、ワークフローの解説は以上とします。
詳細が気になる方は、論文から実装へ:スクラッチ開発者のためのAIエージェント入門 | 株式会社ARISE analytics(アライズ アナリティクス)の記事をご参照ください!
AIエージェントのセキュリティリスク
本章では、AIエージェントのワークフローに沿って、内部実行の知覚、脳、行動、そして、相互作用のAgent2Agent、Agent2Memory、Agent2Environmentそれぞれについてのセキュリティリスクの攻撃例・防御例を挙げていきます。
内部実行(Intra execution)のセキュリティリスク
知覚 (Perception)
知覚モジュールでは、マルチモーダル・マルチステップ(初期のユーザー入力、途中のサブタスクのプロンプト、人間からのフィードバック)データ処理を含みます。基本的には、プロンプトを通じて行われるため、プロンプトに関連するリスクがAIエージェントにとって重要な問題になります。
敵対的攻撃(Adversarial Attack)は、誤ったまたは偏った出力を生成するために、誤解を招くまたは特別に作成されたプロンプトを入力して、脳モジュールを混乱させたり騙したりする攻撃です。知覚モジュールに対する敵対的攻撃には、プロンプトインジェクション攻撃(Prompt Injection Attack)、間接的なプロンプトインジェクション攻撃、および脱獄攻撃(Jailbreak Attack)が含まれます。
| 攻撃手法 | 概要 | 攻撃例 | 防御例 |
| プロンプトインジェクション攻撃 | 悪意のあるテキストを入力プロンプトに挿入し、言語モデルに誤った出力を生成させる悪意のあるプロンプト操作技術 |
・悪意のあるユーザーがプロンプトインジェクションを利用し、リモートコード実行(RCE)を実現し、統合アプリケーションのリモート権限を取得 [96] ・悪意のあるSQLクエリをAIエージェントに生成させ、データの整合性やセキュリティを損なう可能性 [127] |
・階層的な指示権限を確立し、合成データ生成やコンテキスト蒸留によるモデルの強化 [168] ・LLM統合フレームワークのソースコードをスキャンし、RCE脆弱性を検出する静的解析 [96] ・整合性、ソース識別、攻撃検出可能性、ユーティリティ保持を考慮したシールド防御を導入 [72] |
| 間接的プロンプトインジェクション攻撃 | AIエージェントが外部リソースからの有効な指示と無効な指示を区別できないことを悪用し、攻撃者がAIエージェント、ウェブページ、その他のデータソースに指示テキストを注入する攻撃 |
・AIエージェントがウェブプラグインを介して取得したデータを指示と誤認し、過去の会話の抽出やフィッシングリンクの挿入、GitHubコードの盗難 [204]、機密情報の送信 [185] が発生する可能性 |
・AIエージェントと外部リソースの相互作用に明示的な制約を課す [185] ・AIエージェントの微調整 [196, 204] や整合性の向上 [121]、プロンプトエンジニアリングや後処理型分類器ベースのセキュリティ対策 [68] |
| 脱獄攻撃 | AIエージェントがユーザー指示に騙されやすいという特性を悪用し、セキュリティや倫理ガイドラインを回避させ、有害な応答を生成させる |
・ユーザーが役割演技のペルソナを採用したり [182]、「Do Anything Now (DAN)」モードを起動したりすることで、倫理的に問題のある応答を生成させる ・政治的、民族的、性別に偏った発言や攻撃的なコメントをAIエージェントに生成させる |
・フィルタリングベースのアプローチ [145] ・ユーザー入力のすべてのサブストリングの毒性を代替モデルを使用して分析する認定防御 [77] ・AIエージェントが自己評価を行うマルチエージェントディベート(議論とフィードバックによる) [21] |
脳(Brain)
脳モジュールは、主に大規模言語モデル(LLM)で構成されており、知覚モジュールからのプロンプトを処理し、推論・計画・意思決定を行います。
LLMというコアコンポーネントはバックドア攻撃に対して脆弱です。また、わずかな入力の変更に対する堅牢性が不十分であり、これがミスアライメントや幻覚を引き起こします。さらに、脳の推論構造である「チェーン・オブ・ソート(CoT)」に関しては、タスクが複雑で長期的な計画を必要とする場合、誤った計画を立てやすく、これが計画に対するリスクを露呈させます。
| リスク名 | 概要 | 例 | 防御策 |
| バックドア攻撃(Backdoor Attack) |
脳のLLM内にバックドアを挿入し、通常の入力には正常に動作しながら、特定の基準に合致する入力には悪意のある出力を生成させる攻撃。 ・主にトレーニング中にデータを汚染することでバックドアを埋め込む。 ・AIエージェントは外部コンテキストを収集するために環境と相互作用し、攻撃者にとって多様な攻撃ベクターを提供する。 |
・製品推薦を尋ねた際に、バックドアトリガーが作動し、特定の製品を推薦。 ・友人にメールを送るよう指示した際、フィッシングリンクを挿入し、タスク完了として報告 [34]。 |
・モデルの粒度に限らず、エージェントベースの防御手段の研究が必要。 ・モデルベースの防御手法:毒データからのトリガー排除 [33]、バックドア関連のニューロン除去 [76]、トリガーの回復 [18]。 |
| ミスアライメント(Misalignment) |
開発者の意図と実際の動作の間に不一致が生じ、倫理的・社会的リスクを引き起こす。
2. 人間とエージェントの不整合 [8,129,131,175] 3. 具現化環境の不整合 [36,141,159]。 |
・差別、ヘイトスピーチ、誤情報などが発生。 ・100サンプルで88%の成功率でChatGPTを「ジャイルブレイク」し、AIエージェントの脳内の偏見を暴露 [8]。 |
・RLHFの微調整 [121] を活用。 ・オンラインRL環境で報酬を収集し整合性を達成 [36]。 ・TWOSOME フレームワークを導入し、行動確率を計算することで無効な行動を抑制 [159]。 |
| 幻覚(Hallucination) | AIエージェントが提供されたソースコンテンツから逸脱した発言や誤情報を生成。 |
・エージェント数の増加で通信の複雑化により、情報の歪みや誤解が発生 [125]。 ・AIが誤ったメールアドレスを生成し、秘密ノートを共有する [141]。 |
・マルチエージェント協力で幻覚の削減 [16,35]。 ・RAG、内部制約 [16,24]、後処理(知識グラフを活用、LURE指標を利用し幻覚部分を修正 [214])。 |
| 計画に対するリスク(Planning Threat) | AIエージェントが複雑な長期計画で欠陥のある計画を生成する可能性。 |
・思考の連鎖(CoT) が「エラー増幅器」となり、初期の小さな間違いが拡大し、最終的に失敗に至る [71]。 |
・ポリシーベースの憲法的ガイドラインを確立 [63]。 ・文脈自由文法(CFG) を使用し、エージェントの制約を表現 [88]。 |
行動(Action)
エージェント内には複雑な内部実行プロセスが存在するため、内部状態の監視を難しくし、潜在的に多数のセキュリティリスクを引き起こす可能性があります。
行動のリスクは2つの方向に分類しています。1つは、エージェントとツール間の通信プロセス中に発生するリスク(つまり、入力、観察、最終回答で発生するもの)で、これをAgent2Toolリスクと呼びます。もう一つは、エージェントが使用するツールやAPI自体に内在するリスク(つまり、アクション実行で発生するもの)で、これをサプライチェーンリスクと呼びます。これらのAPIを使用することにより、攻撃に対する脆弱性が増し、エージェントは観察や最終回答での誤情報によって影響を受ける可能性があります。
| リスクカテゴリ | 概要 | 例 | 防御策 |
| Agent2Tool |
ツールとエージェント間での情報交換に関連する危険のこと ・アクティブモード: リスクはLLMが提供するアクション入力から発生する。 ・パッシブモード: ツールの正常な使用に関する観察結果や最終回答の傍受から生じる。 |
・パッシブモード:傍受によりユーザーのプライバシーが侵害され、エージェントが送信するデータが第三者企業に不本意に開示される可能性 [144, 149] |
・しかし、このアプローチはエージェントに追加の計算および通信コストを課す |
| サプライチェーン | ツール自体のセキュリティ脆弱性や、バッファオーバーフロー、SQLインジェクション、クロスサイトスクリプティング攻撃を通じたツールの侵害 |
・Webpilot: ChatGPT向けの悪意あるプラグインとして設計され、ChatGPTのチャットセッションを制御し、ユーザーの会話履歴を外部に抜き取る [39] |
・エージェントが信頼できるツールのみを呼び出すように制限 ・この分野の研究はほとんど言及されていない |
相互作用のリスク
Agent2Agent
単一エージェントシステムは特定のタスクを個別に解決することに優れていますが、マルチエージェントシステムは複数のエージェントの協力的な努力を活用して、より複雑な目標を達成し、優れた問題解決能力を発揮します。
一方で、マルチエージェントの相互作用は、AIエージェントに新たな攻撃面を追加しており、大きく分けて協力的相互作用のリスクと競争的相互作用のリスクに分類できます。
| リスクの種類 | 概要 | 例 | 防御策 |
| 協力的相互作用のリスク | 複数のエージェントが同じ目標に向かって協力する際に存在する潜在的なリスク |
・エージェント間の頻繁な協力が小さな幻覚を増幅する可能性がある。[58] ・単一のエージェントのエラーや誤情報が迅速に広がり、誤った意思決定や行動を引き起こす。[123] ・エージェント間の接続性を悪用し、感染が急速に広がることで、スパムや個人データの流出が発生する。[23] |
・幻覚を軽減するために、クロスエグザミネーション [133] や外部のサポートフィードバック [106] などの技術を活用し、エージェントの出力の質を向上させる。 ・協力的なフレームワークは、脱獄攻撃に対する防御の可能性を持つ。[203] |
| 競争的相互作用のリスク | 各競争者が異なる視点を持ち、複数のラウンドにわたって議論を行いタスクを完了する際に、激しい競争関係が発生し、エージェント間の情報フローが信頼できなくなる。 | 競争相手を誤導し、パフォーマンスを低下させるために、敵対的な入力を生成する戦術が取られる。[189] |
・未解決の研究課題として残っている。(エージェントの「脳」の出力を制御することは難しく、計画プロセスに制約を組み込むと、エージェントの有効性に影響を与える可能性がある。) |
Agent2Memory
AIエージェントシステム内のメモリ相互作用は、エージェントの使用中に情報を保存および取得することを含みます。メモリはAIエージェントの運用において重要な役割を果たし、以下の3つの重要なフェーズがあります。
-
エージェントが環境から情報を収集し、それをメモリに保存する。
-
保存後、エージェントはこの情報を処理して、より使いやすい形に変換する。
-
エージェントは処理された情報を使用して、次の行動を指示およびガイドする。
メモリ相互作用により、エージェントはユーザーの好みを記録し、以前の相互作用から洞察を得て、価値のある情報を同化し、この得られた知識を使用してサービスの質を向上させることができます。しかし、これらの相互作用は慎重に管理する必要があり、大きく短期メモリ相互作用のリスクと長期メモリ相互作用のリスクの2種類のセキュリティリスクがあります。
| リスクの種類 | 概要 | 例 | 対応策 |
| 短期メモリ相互作用のリスク | AIエージェントの短期メモリは、人間の作業記憶のように機能し、一時的な情報を保持する。しかし、トークン制限による作業記憶容量の制約があり、広範な文脈の保持が困難で、連続的推論やマルチエージェントシステムでの知識共有を阻害する。また、エージェント間のメモリの非同期化が目標解決に影響を与える可能性がある。[211] |
・強力なエピソード記憶と対話間の継続性がなければ、エージェントは高度な問題解決に不可欠な複雑な連続的推論タスクに苦労する。 |
トークン制限による作業記憶容量の制約
・位置補間の非均一性を活用し、コンテキストウィンドウを256kから2048kに拡張。 ・過去のインコンテキストコンテンツの圧縮 [47, 65, 95, 118] ・要約モデルを展開し、作業記憶内の情報を整理。 非同期への対応
・エージェント間の共通理解を促進するメモリ駆動のコミュニケーションフレームワーク [104] |
| 長期メモリ相互作用のリスク |
長期メモリの保存と取得はベクターデータベースに依存しており、主に2つのプロセスで動作する。
2. クエリ処理: データを埋め込みに変換し、保存済み埋め込みと比較し最適な一致を検索。
これにより、RAG(Retrieval-Augmented Generation)との連携が新たなセキュリティリスクを生む。 |
インデックス作成プロセスにおけるデータ汚染
・敵対的な自己複製プロンプトをワームとして使用し、RAGアプリケーションのデータベースを毒殺し、個人情報を抽出。[23] RAGとベクターデータベースのプライバシー問題
・埋め込みの逆変換によって個人情報が再構築される可能性。[84, 111, 152] 幻覚や不整合に対する生成リスク
・長期メモリの分類欠如により、不適切な取得から情報の矛盾が発生。[56] |
特に記載なし |
Agent2Environment
環境との総合作用におけるリスクについて、シミュレートされた環境、開発&テスト環境、コンピューティングリソース管理環境、物理環境の4つの分類でリスクがまとめられています。
| 環境カテゴリ | 概要 | 例 | 防御策 |
| シミュレートされた環境 | AIエージェントのシミュレート環境は、エージェントが操作し、相互作用するデジタルシステムを指しており、それらの環境に固有のリスクが存在している |
ユーザーの擬人化のリスク: 誤用のリスク: |
・厳格な倫理的ガイドラインと監視機構の実施が重要 |
| 開発&テスト環境 | ほとんどのAIエージェント開発者は、他の開発済みLLMのAPIを使用しており、特にサードパーティのLLM APIプロバイダーの信頼性に関する潜在的なセキュリティ問題が存在する |
LLM APIのバックドア攻撃: ・AIエージェントの「脳」が他者によって制御される可能性 |
戦略的アプローチの採用: ・uardRails AI、NeMo Guardrails などを活用し、LLMのセキュリティガードレールを確立 キャッシングとログ管理: ・Redis や GPTCache による安全なキャッシングメカニズム ・MLFlow や Weights & Biases によるログ管理 モデル評価: ・LLMの精度やバイアスを評価し、適切に調整 |
| コンピューティングリソース管理環境 | AIエージェントのコンピューティングリソース管理環境は、CPU、GPU、メモリなどの計算リソースの最適化を監督するが、不完全な管理環境は、エージェントを攻撃に対して脆弱にする可能性がある |
リソース枯渇攻撃: ・過剰なリソース消費を強要し、DoS攻撃を引き起こす [46, 52] 非効率なリソース割り当て: ・不適切なプロンプト処理がAIエージェントのリソースを浪費 [62] エージェント間の不十分な隔離: ・悪意のあるエージェントが他のエージェントに干渉し、情報漏洩や不正アクセスが発生 [4, 89, 151] AIエージェントのリソース仕様の未監視: ・リソース消費の急激な増加などの異常行動が見逃される [4] |
・未記載(適切な制限や監視の仕組みが必要と考えられる) |
| 物理環境 | エージェントはセンサー、カメラ、マイクなどを通じて情物理環境の情報を収集するが、多様なセキュリティリスクが存在する |
Bluetooth攻撃の脆弱性: ・Bluetoothモジュールが統合されたデバイスは、情報漏洩やDoS攻撃を受ける可能性 [114] LLMのランダム性による誤作動: ・エージェントがハードウェアデバイスに誤った指示を送る可能性 [153] |
信頼性の高いハードウェアの使用: ・ファームウェアの更新を常に最新に保つ 物理環境データのセキュリティチェック: ・エージェントが収集したデータを分析し、リスクを迅速にフィルタリング |
今後の研究動向について
最後に今後の研究の方向性についてまとめられていたので、概要をまとめます。
-
方向性1:効率的かつ効果的な入力検査
-
知覚に対するリスクに対処するために、ユーザー入力の自動およびリアルタイム検査レベルを向上させる [142, 194]
-
-
方向性2:AIエージェントにおけるバイアスと公平性
-
エージェントがさまざまなタスクに関与する複雑さが増す中で、バイアスを特定し軽減する [48, 157]
-
-
方向性3:厳格なツール使用監査
-
AIエージェントのツール相互作用における課題に対処するための有望な将来の方向性は、厳格なツール使用監査の実施 [207]
-
-
方向性4:AIエージェントにおける健全な安全評価基準
-
AIエージェントエコシステム全体の安全基準の設計標準についてはまだ統一されたコンセンサスがない
-
エージェントエコシステムの一部のみの評価結果を提供する研究は存在する[198, 166m 141]が、多くの評価問題が未解決のまま残されている。
-
-
方向性5:堅固なエージェント開発および展開ポリシー
-
エージェントの開発および展開のための堅固なポリシーの策定と実施[63]
-
-
方向性6:最適な相互作用アーキテクチャ
-
AIエージェントのセキュリティ面での相互作用アーキテクチャの設計と実装は、堅牢なシステムを改善することを目的とした重要な研究分野 [54, 82, 104, 117 (← これらの研究はエージェント間の依存関係を考慮していない) ]
-
-
方向性7:堅牢なメモリ管理
-
メモリを安全に管理する方法が中心的な課題となり、洗練されたベンチマークと取得メカニズムの開発が必要
-
おわりに
AIエージェントのセキュリティは、社会実装に伴い今後ますます重要な課題となっていくと考えられます。私たちは、AIエージェントの活用を推進し社会課題を解決していくと共に、安全に使用するために、使用に伴うリスクにも対処していく必要があります。そのためには、新しい技術と戦略をアップデートし続ける必要があり、研究と実践の両面での努力が求められています。今後の進展に期待しつつ、私たち一人ひとりがセキュリティ意識を高めることが、より安全なAI社会の実現に繋がると思います。