始めに
はじめまして、2022年4月に新卒として入社した Customer Analytics Division / DX Technology Unit の日比です。弊社では、より高性能なAIを開発するためのスキル研鑽として社内ブログでのアウトプットが盛んに行われています。本日はその中で私が執筆した「ワクチン接種後の体温変化をガウス過程回帰してみた」という記事について共有させていただきます。
0. 概要
今回はタイトルにもあるようにガウス過程回帰について自分の理解を書こうと思います。「ガウス過程ってなに?」って人も多いかと思いますが、「ベイズ最適化は知っているよ」って人は多いのではないでしょうか? ベイズ最適化はガウス過程回帰の結果を用いてパラメーターの最適値を探すチューニング手法になっており、実は知らない間にガウス過程回帰にお世話になっているのです。少しガウス過程回帰について興味が出てきましたか?
この記事では、始めに前提知識として必要な多変量ガウス分布およびリッジ回帰について説明した後、本題であるガウス過程回帰の話に移ります(リッジ回帰は重み\(\boldsymbol{w}\)がガウス分布からサンプリングされるってどういう事かをイメージ付きやすくするために執筆しているので、飛ばしてもらってもかまいません)。そして、ガウス過程回帰をもちいて実際にワクチン接種後の体温変化を回帰してみたので、その結果を共有したいと思います。
1. 多変量ガウス分布
1-1 概要
始めに多変量ガウス分布について確認しておきます。皆さんご存知1次元のガウス分布は以下の通りです。
\(\cal{N}(x | \mu,\sigma) =\frac{1}{\sqrt{2\pi}\sigma}\exp(-\frac{(x-\mu)^2}{2\sigma^2}) \tag{1.1}\)
これを\(D\)次元の多変量ガウス分布に変換すると以下です。
\(\mathcal{N}( \mathbf{x} | \boldsymbol{\mu},\Sigma) =\frac{1}{(\sqrt{2\pi})^D\sqrt|\Sigma|}\exp(-\frac{1}{2}(\mathbf{x}-\boldsymbol{\mu})^T\Sigma^{-1}(\mathbf{x}-\boldsymbol{\mu})) \tag{1.2}\)
この時 \(\mathbf{x},\boldsymbol{\mu}\)は\(D\)次元ベクトルで \(\Sigma\) は \(D\times D\) の共分散行列です。共分散行列は期待値\(E[X]\) を用いて、
$$
\Sigma = E[\mathbf{x}\mathbf{x}^T] – E[\mathbf{x}]E[\mathbf{x}]^T \tag{1.3}
$$
と表す事が出来ます。名前からも察しがつくように \(\Sigma\)によって、下図のようにガウス分布の相関が変わっていきます。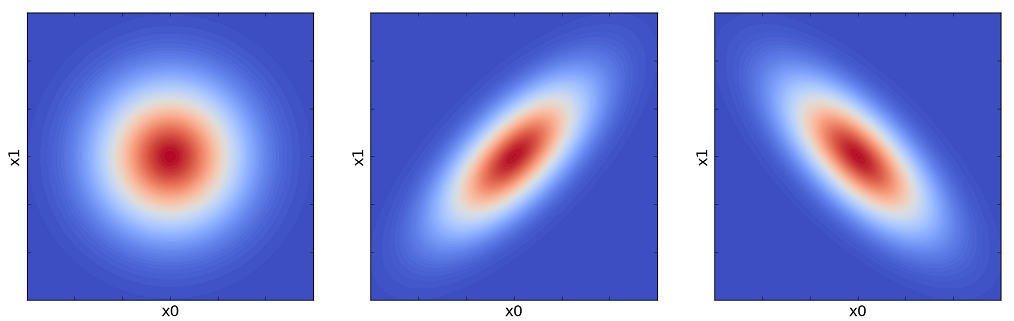
多変量正規分布 – 機械学習に詳しくなりたいブログ より引用
左から,
$$
\Sigma = \left( \begin{array}{c}
1 & 0 \\
0 & 1
\end{array} \right), \left( \begin{array}{c}
1 & 0.7 \\
0.7 & 1
\end{array} \right), \left( \begin{array}{c}
1 & -0.7 \\
-0.7 & 1
\end{array} \right)
$$
としたときの2次元ガウス分布を示しています。
1-2 条件付き分布
さて、多変量ガウス分布のイメージ着いたところで、次に条件付き分布について考えていきます。ここでいう条件付きとは、多変量ガウス分布からサンプリングされる ベクトル \(\mathbf{x}\) のうち、いくつかの値が固定されることを意味しています。例えば、
$$\mathbf{x} = \left( \begin{array}{c}
\mathbf{x}_{1} \\
\mathbf{x}_{2}
\end{array} \right)\sim p(\mathbf{x}_{1},\mathbf{x}_{2}) = \mathcal{N}\left(\begin{array}{l}\left(\begin{array}{l}
\boldsymbol{\mu_{1}} \\
\boldsymbol{\mu_{2}}
\end{array}\right),\left(
\begin{array}{l}
\Sigma_{11} & \Sigma_{12} \\
\Sigma_{21} & \Sigma_{22}
\end{array}\right)\end{array} \right) \tag{1-2.1}
$$
と \(\mathbf{x}\) を \(\mathbf{x_{1}}\) と \(\mathbf{x_{2}}\) に分割して考えたときに、\(\mathbf{x_{1}}\) の値が固定された時の \(\mathbf{x_{2}}\) が従う確率分布
$$
\mathbf{x}_{2}
\sim
p(\mathbf{x}_{2}|\mathbf{x}_{1}) = \mathcal{N}( ? , ? ) \tag{1-2.2}
$$
で?に当てはまる平均値や共分散行列について考えてみます。イメージとしては以下の図のようになっています。 2次元ガウス分布に対して \(x_{b}\) が固定されていないときの \(x_{a}\) の確率分布 \(p(x_{a})\) と \(x_{b}\) がある値に固定された時の \(x_{a}\) の確率分布 \(p(x_{a}|x_{b})\) を比較してみると平均の位置と分散が変化していることがイメージ出来るでしょうか。
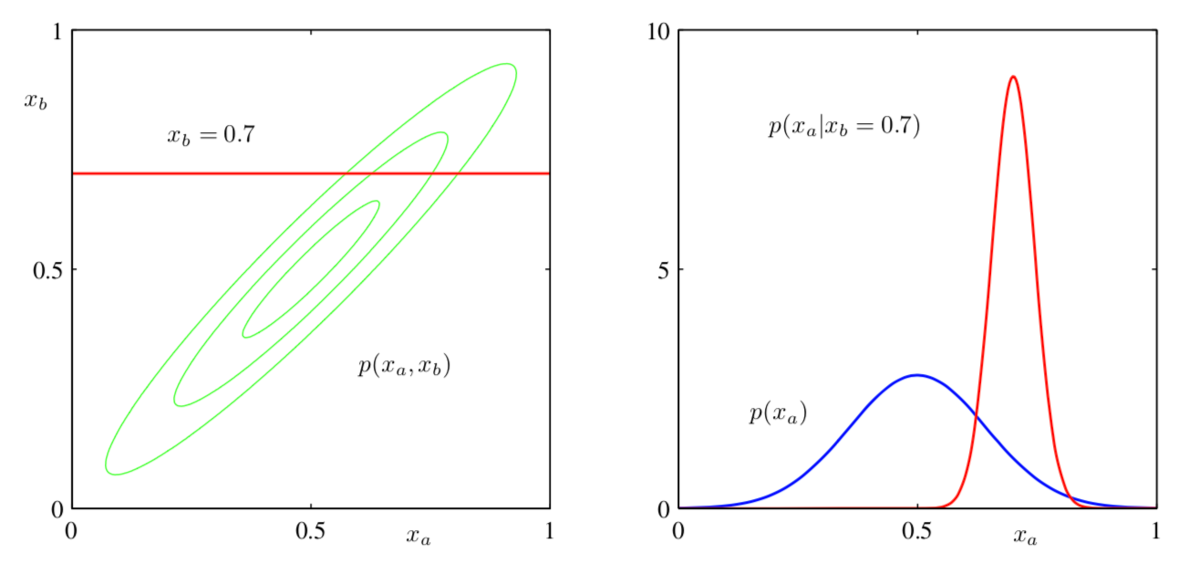
条件付き正規分布(Conditional Gaussian distributions)|改めて理解する多次元正規分布 #2 – Liberal Art’s diary より引用
これを具体的に頑張って計算してみると、結果として以下を得ます。
$$
p(\mathbf{x}_{2}|\mathbf{x}_{1}) = \mathcal{N}( \boldsymbol{\mu}_{2} + \Sigma_{21}\Sigma_{11}^{-1}(\mathbf{x}_{1}-\boldsymbol{\mu}_{1}) , \Sigma_{22} – \Sigma_{21}\Sigma_{11}^{-1}\Sigma_{12} )
\tag{1-2.3}
$$
具体的な証明は示しませんが、\(\mathbf{x}_{1}\) が決まることで平均の位置が \(\Sigma_{21}\Sigma_{11}^{-1}(\mathbf{x}_{1}-\boldsymbol{\mu}_{1})\) だけずれ、 分散が \(\Sigma_{21}\Sigma_{11}^{-1}\Sigma_{12}\) だけ小さくなる事が分かります。
2. 線形回帰とリッジ回帰
次に、リッジ回帰について知っておいた方がガウス過程回帰のイメージが付きやすいと思うのでリッジ回帰について説明します。また、リッジ回帰は線形回帰が解けない(逆行列が存在しない)場合などに有用な手法なので、線形回帰についても簡単に復習しておきます。
2-1 線形回帰
線形回帰とは、例えば
$$
\begin{array}{l}
\hat{y} = w_0 + w_1x + w_2x^2 \\
\hat{y} = w_0 + w_1x + w_2x^2 + w_3\sin{x}
\end{array}
$$
のように係数 \(\boldsymbol{w} = (w_0,w_1,w_2 ..)^T\) に対して線形になるような式を考えるモデルでした。より一般的には、
$$
\hat{y} = w_0 + w_1\phi_1(x) + w_2\phi_2(x) + w_3\phi_3(x) + … + w_H\phi_H(x)
\tag{2-1.1}
$$
のように任意の関数\(\phi_n(x)\)で書くことが出来ます。ここで\(\phi_n(x)\)を基底関数と呼ぶことにします。これをN個のデータかつ \(x\) がベクトルである時を考えると、
$$
\left( \begin{array}{c}
\hat{y}_1 \\
\hat{y}_2 \\
\vdots \\
\hat{y}_N
\end{array} \right) = \left( \begin{array}{c}
\phi_0(\mathbf{x}_1) \quad \phi_1(\mathbf{x}_1) \quad \phi_2(\mathbf{x}_1) \quad \cdots \quad \phi_H(\mathbf{x}_1) \\
\phi_0(\mathbf{x}_2) \quad \phi_1(\mathbf{x}_2) \quad \phi_2(\mathbf{x}_2) \quad \cdots \quad \phi_H(\mathbf{x}_2) \\
\vdots \\
\phi_0(\mathbf{x}_N) \quad \phi_1(\mathbf{x}_N) \quad \phi_2(\mathbf{x}_N) \quad \cdots \quad \phi_H(\mathbf{x}_N)
\end{array} \right)
\left( \begin{array}{c}
w_0 \\
w_1 \\
\vdots \\
\vdots \\
w_H
\end{array} \right)
\tag{2-1.2}
$$
ここで、\(\phi_0(\mathbf{x}) \equiv 1\) と定義しています。また、式のベクトルおよび行列を左から \(hat{\mathbf{y}}, \Phi, \boldsymbol{w}\) と表記することとします。
線形回帰では、あるデータセット \((\mathbf{Y},\mathbf{X})\) に対して \(\boldsymbol{w}\) は以下の式で与えられます。
$$
\boldsymbol{w} = (\Phi^T\Phi)^{-1}\Phi^T\mathbf{Y}
\tag{2-1.3}
$$
つまり、\((\Phi^T\Phi)\) の逆行列があればこの問題は解けるということです。
2-2 正則化としてのリッジ回帰
線形回帰では\((\Phi^T\Phi)\) の逆行列があればうまく回帰をすることが出来るとわかりました。ただ、必ずしも逆行列があるとは限りません。例えば基底関数の数 \(H\) が データ数 \(N\) よりも少ない場合は \((\Phi^T\Phi)\) のランクが \(H\) より小さくなるため逆行列が存在しません。
リッジ回帰ではいわゆるL2ノルムを考えることでこの問題を回避します。
回帰ではよく二乗誤差の最小化を考えて \(\boldsymbol{w}\) を求めます。この際、二乗誤差に加えて\(\boldsymbol{w}\) の大きさを加える正則化を考えます。すなわち、
$$
Err = (\boldsymbol{Y} – \boldsymbol{\Phi}\boldsymbol{w})^2 + \alpha\boldsymbol{w}^T\boldsymbol{w} \tag{2-2.1}
$$
を考えます。これを\(\boldsymbol{w}\)で微分し、その値が0となる\(\boldsymbol{w}\)について解くと以下が得られます。
$$
\boldsymbol{w} = (\Phi^T\Phi + \alpha\mathbf{I})^{-1}\Phi^T\mathbf{Y}
\tag{2-2.2}
$$
結果的には、線形回帰の解の時と比べて \((\Phi^T\Phi)\) に \(\alpha\mathbf{I}\) が足されたことが分かります。ここで \(\alpha\) はハイパーパラメータで、\(\mathbf{I}\) は単位行列です。この \((\Phi^T\Phi + \alpha\mathbf{I})\) には必ず逆行列があるのでうまく解を求めることが出来ます。
2-3 ベイズ的観点で見るリッジ回帰
正則化として導入した \(\alpha\boldsymbol{w}^T\boldsymbol{w}\) ですが、実は確率モデルから自然に導くことが可能です。
ある\(N\)点のデータセット \( (Y,\Phi(X)) \) が得られたときに、係数が \(\boldsymbol{w}\)であった確率を示す確率密度関数を \(p(\boldsymbol{w}|Y,\Phi(X))\) とします。回帰は \(p(\boldsymbol{w}|Y,\Phi(X))\)が最も大きな値を取る \(\boldsymbol{w}\) を計算することと同じになるので、 \(p(\boldsymbol{w}|Y,\Phi(X))\) が最大になる条件を考えてみましょう。\(\boldsymbol{w}\) の条件付き確率密度関数はベイズの定理より以下のように変換できます。
$$
p(\boldsymbol{w}|Y,\Phi(X)) = p(Y|\boldsymbol{w}, \Phi(X)) p(\boldsymbol{w})
\tag{2-3.1}
$$
なお、分母成分は定数であり、今回の問題には影響しないので省略しました。また、\(p(\boldsymbol{w}|\Phi(X)) = p(\boldsymbol{w})\) を用いています。\(Y\) の条件付き分布については、回帰でえられる \(\Phi(X)\boldsymbol{w}\) にガウス分布するノイズ \(\epsilon\) が乗っかった値が \(Y\) になると考えると,
$$
p(Y|\boldsymbol{w}, \Phi(X)) = \mathcal{N}(Y|\Phi(X)\boldsymbol{w}, \sigma^2\boldsymbol{I}_N)
\tag{2-3.2}
$$
と書くことが出来ます。
\(p(\boldsymbol{w})\) に関してもガウス分布を仮定しましょう。すなわち、
$$
p(\boldsymbol{w}) = \mathcal{N}(\boldsymbol{w}|0, \lambda^2\boldsymbol{I}_{H})
\tag{2-3.3}
$$
です。なお、\(\boldsymbol{w}\) の各成分は完全に無相関なガウス分布からサンプリングされるとしています。それでは、いつものように log を取って具体的に最大化すべき式を導出します。
$$
\log{p(\boldsymbol{w}|Y,\Phi)} = -\frac{1}{2\sigma^2}\sum_{n=1}^{N}(y_{n}-\boldsymbol{\phi}(\mathbf{x}_{n})\boldsymbol{w})^2 – \frac{1}{2\lambda^2}\sum_{i=1}^{H}w_{i} + C \\
\propto – \{ (\boldsymbol{Y}-\Phi\boldsymbol{w})^2 + \alpha\boldsymbol{w}^T\boldsymbol{w}\}
\tag{2-3.4}
$$
得られた結果と、前節で導入したリッジ回帰の式(2-2.1)を比較すると完全に一致しています。すなわち、正則化として\(\boldsymbol{w}\) の大きさを加えることと、\(\boldsymbol{w}\) を多変量ガウス分布からサンプリングされる値として扱う事は同じ結果を導くのです。ここで重要な点として、\(\boldsymbol{w}\) が多変量ガウス分布からサンプリングされた値であるという事を覚えておいて、いよいよガウス過程回帰について見ていきましょう。
3. ガウス過程回帰
ようやく本題であるガウス過程回帰に移ります。
3-1 ガウス過程
ここでも、式(2-3.3) と同様に\(\boldsymbol{w}\) はガウス分布からサンプリングされるものとします。あるデータセット\((\boldsymbol{Y},\boldsymbol{X})\) が与えられると、\(\Phi(\boldsymbol{X})\) は定数と考えられるので、\(\boldsymbol{Y}\) はガウス分布にしたがう\(\boldsymbol{w}\) を \(\Phi\) で線形写像したものと考えられます。したがって\(\boldsymbol{Y}\) もガウス分布に従います。この時の期待値と共分散行列(式(1.3))を計算すると以下のようになります。
$$
E[\boldsymbol{Y}] = E[\Phi\boldsymbol{w}] = \Phi E[\boldsymbol{w}] = 0 \tag{3-1.1}\
$$
$$
\Sigma = \lambda^2\Phi\Phi^T \tag{3-1.2}\
$$
すなわち,\(\boldsymbol{Y}\) が従うガウス分布は以下のように表されます。
$$
\boldsymbol{Y} \sim \mathcal{N}(0,\lambda^2\boldsymbol{\Phi\Phi}^T) \tag{3-1.3}
$$
ここで注目すべき点は、\(\boldsymbol{w}\) は期待値が取られて消去されていることです。これによって、例え基底関数の数が高次、あるいは無限次元であったとしても、具体的に\(\boldsymbol{w}\) を求める必要はなく、\(\lambda^2\boldsymbol{\Phi\Phi}^T\) によってのみ\(\boldsymbol{Y}\) が従う分布が表現されます。このように、どのような\(N\)個の入力\(\boldsymbol{X}=(\mathbf{x_{1}}, …, \mathbf{x_{N}})\) についても、対応する\(\boldsymbol{Y} = (y_1, … y_N)\) が多変量ガウス分布に従う時、\(\boldsymbol{X}と\boldsymbol{Y}\) はガウス過程に従う、と言います。
なお、 \(\boldsymbol{Y}\) の平均値が0になってしまっていますが、あらかじめ \(\boldsymbol{Y}\) から \(\boldsymbol{Y}\) の平均値を引いておけば必ず0になるので、そのような処理を行っているものとして今後の議論を進めます。
3-2 カーネルトリック
次に\(\boldsymbol{\Phi\Phi}^T\) の計算について考えます。単純な方法として、任意の基底関数を要素に持つベクトル \(\phi(\mathbf{x}) = (\phi_1(\mathbf{x}), … , \phi_H(\mathbf{x}))\) を定めて計算するように思うかもしれませんが、その必要はありません。実際にほしい値は、基底関数ベクトルの内積である以下の式の値です。
$$
k_{nn’}(\mathbf{x}_{n}, \mathbf{x}_{n’}) = \phi(\mathbf{x}_{n})^T\phi(\mathbf{x}_{n’}) \tag{3-2.1}
$$
したがって、\(\phi(\mathbf{x})\) を明示的に与えるのではなく、この内積の値を与える関数を与えてやれば良いのです。その関数の事をカーネル関数と呼び、ガウスカーネル(RBFカーネル)、線形カーネル、指数カーネルなど様々な種類のカーネルが存在します。また、このように\(\phi\) を直接表現することを避けてカーネルだけで内積を計算する事をカーネルトリックと言います。
一つ例としてガウスカーネルは以下の式で与えられます。
$$
k(\mathbf{x}, \mathbf{x’}) = \theta_1 \exp(-\frac{|\mathbf{x}-\mathbf{x’}|^2}{\theta_2}) \tag{3-2.2}
$$
実はこのカーネルの元になっている基底関数を考えると、平均の値が異なる無限個のガウス分布で回帰するモデルになっています。本来の線形回帰であれば無限個の基底関数で回帰することなどできませんが、カーネルを使うことによって非常に高い表現が得られたのです。まさにトリックですね!
3-3 予測値の計算
最後に予測値の計算ですが、1-2章で説明した式を用いれば、既にあるデータセットを用いた条件付き多変量ガウス分布を計算できますし、あたらしい\(x\) に対する \(y\) の予測値(正しくは新しい\(x\) における\(y\) 方向の分布)も計算することが出来ます。
4. ワクチン接種後の体温変化をガウス過程回帰
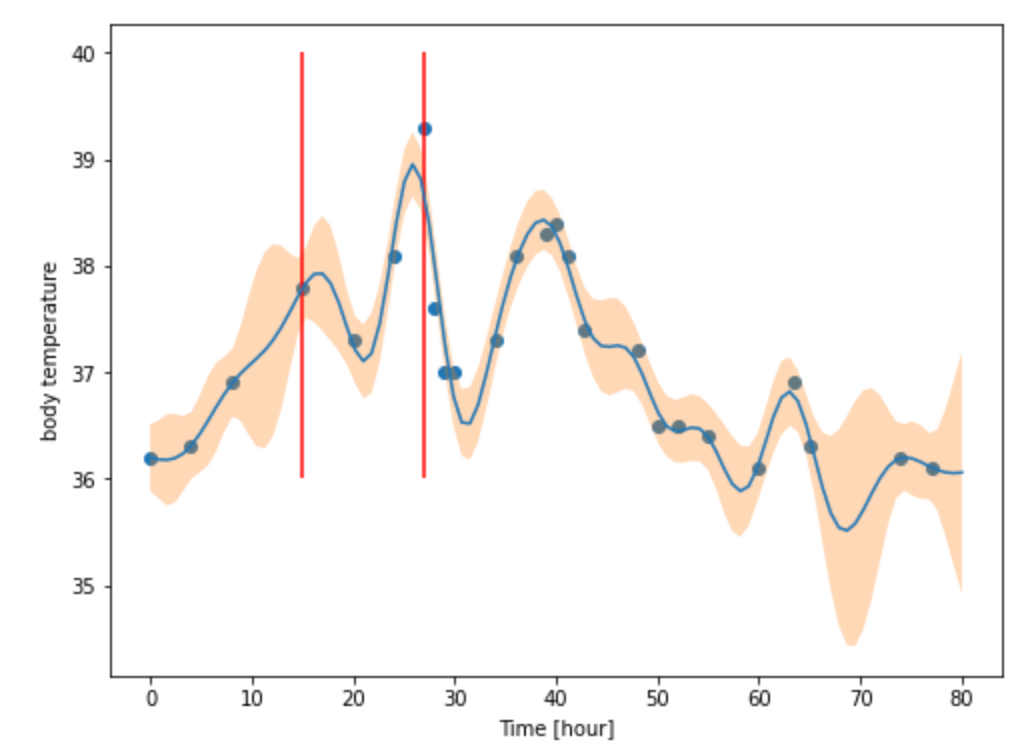
基本的なガウス過程回帰のプロセスが理解できたので、実際に使ってみました。今回は、2回目のワクチン接種をした際の体温変化を回帰してみました。使用したツールはpythonでbayse_optというモジュールのBaysianOptimaizationという関数を使用しています。 青い点が測定点、オレンジのバンドが\(1\sigma\) を表しています。赤い線はロキソニンを服用した時の時間です(面白い形にしたくて、体温上がるまで我慢したのはここだけの話)。非常に複雑な形をしていますが、それっぽく回帰出来ている事が分かります。スゴイですね!!
5. 終わりに
ガウス過程回帰のイメージが理解できたでしょうか? 結局のところ、ガウス過程回帰では各データ点のyの値はある相関を持った多変量ガウス分布からサンプリングされた値であり、その相関はx方向の値とカーネル関数を用いて定義されているのでした。
色々省略して説明したところもあるので、少しわかりづらかったかもしれませんが、これで興味を持った人は是非勉強してみてください。基本的にこの記事は参考文献に記載した本を参考に執筆しているので、詳細を知りたい人はこちらをご購入下さい。また、ベイズ最適化はガウス過程が分かってしまえばイメージは割とすぐに理解できるかなと思います。
以上ガウス過程回帰を使ってみた話でした。次回ワクチンを打つ機会があれば是非ガウス過程回帰を試してみてください。寝ている間に体温がどこまで上がったのかわかるかもしれません。
