Scala×Sparkによる位置情報分析例のご紹介 part2
 この記事をシェアする
この記事をシェアする



こんにちは。Marketing Solution Divisionに所属している2年目データサイエンティストの山嵜です。私はデータ分析を通してマーケティングのサポートを行うBIツールの開発チームに3ヶ月ほど在籍したのち、位置情報を扱う分析チームに移籍しました。こちらのチームではデータ分析として広く一般的に扱われているPythonのみならず、Scala×Sparkを用いて位置情報データ分析を実施しております。
前回の記事ではScala×Sparkを使った位置情報データ分析の例として、Sparkのwindow関数とudfを用いて2点間の距離を求めるコードの実装例をご紹介させて頂きました。今回の記事では、より位置情報特有の話題として、緯度経度⇔メッシュコードの相互変換の実装例をudfを用いずにご紹介したいと思います。
位置情報の利用
前回の記事でも述べましたが、最近では位置情報データを使ったマーケティング活動が注目されてきております。弊社でも、近年位置情報データを用いた分析を幅広くおこなっております。
そこで本日は位置情報をより扱いやすいデータに集約するための方法として、GPS位置情報データから取得される緯度・経度をメッシュコードに相互変換する処理をご紹介したいと思います。さらに、こちらの実装はScala言語と並列分散処理フレームワークSparkを用いており、位置情報のような大規模データを高速に処理することができるので、同じような大規模データを扱っている方は参考にしてみてください。
緯度経度とメッシュコード
まず実装をご紹介する前に、あまり馴染みのないメッシュコードに関して簡単に説明いたします。メッシュコード(引用文中では「地域メッシュ統計」と言及)とは、総務省統計局によると、以下のように定義されております。
地域メッシュ統計とは、緯度・経度に基づき地域を隙間なく網の目(Mesh)の区域に分けて、統計データをそれぞれの区域に編成したものです
つまり、メッシュコードは、緯度経度のような「点」とは異なり、ある程度の幅を持った四角形の「範囲」を示しております(図1参照)。
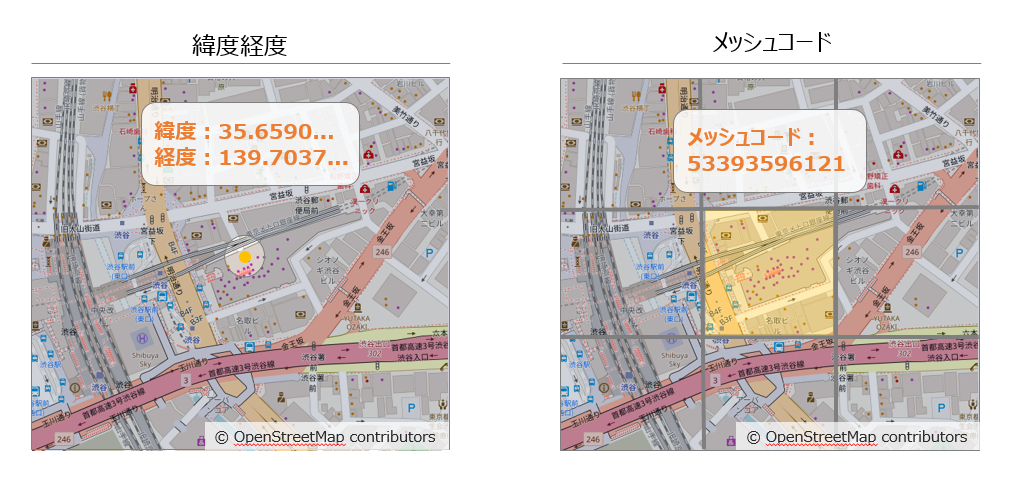 図1:緯度経度とメッシュコードの違い(イメージ図) ※図中の緯度経度とメッシュコードは実際と異なる場合があります。
図1:緯度経度とメッシュコードの違い(イメージ図) ※図中の緯度経度とメッシュコードは実際と異なる場合があります。
また、いくつかの緯度経度の「点」をメッシュコードの「範囲」に変換することで、地域ごとに情報の集約が可能になります。したがって、大規模データをある程度集約した扱いやすい状態にすることができます。
また、メッシュコードは4桁~11桁の数値列から成ります。各桁ごとに区画が定義されており、上位桁から第1次地域区画、第2次地域区画・・・と広域の区画から狭域の区画に絞り込む形で領域が定義されています(表1参照。詳細に関して出典中「4 地域メッシュの区分方法」を参照)。
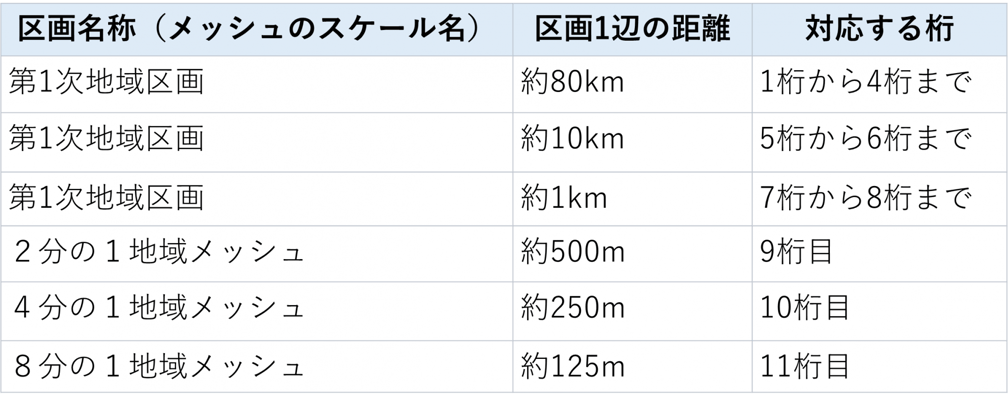 表1:メッシュスケールごとの大きさと対応する桁
表1:メッシュスケールごとの大きさと対応する桁
緯度経度⇒メッシュコードの変換
それでは、実際の実装コードをご紹介いたします。まずは、緯度経度から11桁のメッシュコードへの変換です。総務省統計局の定義に従って実装していきます。今回は緯度経度の表記方法として、10進法を採用します。
import org.apache.spark.sql.Column
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
/**
* 緯度・経度からメッシュコードを計算する。
*
* @param latitude 緯度
* @param longitude 経度
* @return メッシュコード
*/
def coordinatesToMeshCode(latitude: Column, longitude: Column): Column = {
val decimal = new DecimalType(10, 7)
val lat = latitude.cast(decimal)
val lon = longitude.cast(decimal)
def splitByDecimalPoint(input: Column): (Column, Column) = {
val integerPart = input.cast(IntegerType)
val decimalPart = input - integerPart
(integerPart, decimalPart)
}
// 緯度の計算
val (latInt80km, latDecimal80km) = splitByDecimalPoint(lat * 1.5) // 1次メッシュ
val (latInt10km, latDecimal10km) = splitByDecimalPoint(latDecimal80km * 8) // 2次メッシュ
val (latInt1km, latDecimal1km) = splitByDecimalPoint(latDecimal10km * 10) // 3次メッシュ
val (latInt500m, latDecimal500m) = splitByDecimalPoint(latDecimal1km * 2) // 1/2メッシュ
val (latInt250m, latDecimal250m) = splitByDecimalPoint(latDecimal500m * 2) // 1/4メッシュ
val (latInt125m, _) = splitByDecimalPoint(latDecimal250m * 2) // 1/8メッシュ
// 経度の計算
val (lonInt80km, lonDecimal80km) = splitByDecimalPoint(lon - 100) // 1次メッシュ
val (lonInt10km, lonDecimal10km) = splitByDecimalPoint(lonDecimal80km * 8) // 2次メッシュ
val (lonInt1km, lonDecimal1km) = splitByDecimalPoint(lonDecimal10km * 10) // 3次メッシュ
val (lonInt500m, lonDecimal500m) = splitByDecimalPoint(lonDecimal1km * 2) // 1/2メッシュ
val (lonInt250m, lonDecimal250m) = splitByDecimalPoint(lonDecimal500m * 2) // 1/4メッシュ
val (lonInt125m, _) = splitByDecimalPoint(lonDecimal250m * 2) // 1/8メッシュ
// メッシュコードの計算
val meshCode80km = (latInt80km.cast(LongType) * 100 + lonInt80km).cast(StringType)
val meshCode10km = concat(abs(latInt10km).cast(StringType), abs(lonInt10km).cast(StringType))
val meshCode1km = concat(abs(latInt1km).cast(StringType), abs(lonInt1km).cast(StringType))
val meshCode500m = (latInt500m * 2 + lonInt500m + 1).cast(StringType)
val meshCode250m = (latInt250m * 2 + lonInt250m + 1).cast(StringType)
val meshCode125m = (latInt125m * 2 + lonInt125m + 1).cast(StringType)
val meshCode = concat(meshCode80km, meshCode10km, meshCode1km, meshCode500m, meshCode250m, meshCode125m)
meshCode
}
メッシュコード⇒緯度経度の変換
続いて、11桁のメッシュコードから緯度経度への変換です。このとき注意しなければならないのは、メッシュコードは「範囲」にあたるため、中心緯度経度をそのメッシュコードの緯度経度として扱っている点です。また、今回は対応しておりませんが、4~10桁のメッシュコードから緯度経度への変換は、中心座標への補正を適宜調整することで実装することができます。例えば、10桁のメッシュコードから変換する場合には「4分の1地域メッシュ」の中心座標を緯度経度とみなす必要があります。
import org.apache.spark.sql.Column
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
import shapeless.Tuple
/**
* 11桁メッシュの中心緯度・経度を計算。
*
* @param meshCode 11桁メッシュコード
* @return (latitude, longitude) 緯度・経度のタプル
*/
def meshCodeToCoordinatesGPS(meshCode: Column): (Column, Column) = {
// 2分の1地域メッシュ以降のメッシュコードに対応した座標を算出
def encodeMeshValue(input: Column): Column = {
when(input === 1, lit(Array(0, 0)))
.when(input === 2, lit(Array(0, 1)))
.when(input === 3, lit(Array(1, 0)))
.when(input === 4, lit(Array(1, 1)))
}
// 緯度の計算
val lat = (
substring(meshCode, 1, 2) * 2 / 3 + //1次メッシュ
substring(meshCode, 5, 1) * 1 / 12 + //2次メッシュ
substring(meshCode, 7, 1) * 1 / 120 + //3次メッシュ
element_at(encodeMeshValue(substring(meshCode, 9, 1)), 1) * 1 / 240 + //1/2メッシュ
element_at(encodeMeshValue(substring(meshCode, 10, 1)), 1) * 1 / 480 + //1/4メッシュ
element_at(encodeMeshValue(substring(meshCode, 11, 1)), 1) * 1 / 960 + //1/8メッシュ
1.0 * 1 / 1920 //中心座標に補正
)
// 経度の計算
val lon = (
substring(meshCode, 3, 2) + 100 + //1次メッシュ
substring(meshCode, 6, 1) * 1 / 8 + //2次メッシュ
substring(meshCode, 8, 1) * 1 / 80 + //3次メッシュ
element_at(encodeMeshValue(substring(meshCode, 9, 1)), 2) * 1 / 160 + //1/2メッシュ
element_at(encodeMeshValue(substring(meshCode, 10, 1)), 2) * 1 / 320 + //1/4メッシュ
element_at(encodeMeshValue(substring(meshCode, 11, 1)), 2) * 1 / 640 + //1/8メッシュ
1.0 * 1 / 1280 //中心座標に補正
)
(lat, lon)
}
おわりに
今回は、ScalaとSparkを用いて、緯度経度⇔メッシュコードの相互変換の実装例を紹介しました。このようにデータを相互に変換することで、目的に沿った粒度で分析を実施することができます。もしも位置情報データの扱い方で良いアイデアがあれば、ぜひご意見を頂ければと思います。最後になりますが、もしよろしければ、私が過去に執筆したDjango REST Frameworkの記事もご覧いただければと思います。

