初めまして、Advanced Tech Divisionでデータエンジニアをしている對馬(つしま)です。
実証実験等の検証フェーズで構築した機械学習や深層学習を用いた分析モデルをシステムとして商用化する際に、どのようにシステムに組み込めば良いか戸惑うことはありませんか?
今回は私自身のこれまでの経験(長くなるので今度紹介します)をもとに分析モデルを商用化する際に考慮すべきことを5つ書いていきます。
1. そのまま組み込めると思わない
システム化する前に実証実験等の検証フェーズを経てシステム化する流れが一般的かと思いますが、検証フェーズの分析モデルは商用化することを考慮した設計が行われないことが多いです。
これは個人的には当たり前のことだと思っています。なぜなら商用化することを考慮する時間があるなら0.1%でも精度を改善することや分析結果から示唆を得ることに時間を費やすべきだからです。
そのため分析モデルを商用化する際は本ページの2.以降の内容を考慮した開発工数・スケジュールの見積もりすべきです。
2. 分析モデルの中身を理解し、その上で処理単位を細分化する
システムを設計する際は誰しも疎結合になるよう設計すると思いますが、そのためには分析モデルの中身についての理解が必要です。難解になりがちな分析モデルのアルゴリズムを100%理解する必要はなく、大きく①前処理、②学習、③予測の3つのパートに分けてそれぞれの処理の構造・単位は最低限理解する必要があります。
①前処理を例にあげると、検証フェーズでは限られたデータで一括で前処理しているケースが良くあります。商用運用の際は実データが日々蓄積されて行くので、一括処理だといつかはサーバー性能(CPUやメモリ)の限界に達してしまい、大幅な処理時間の劣化や、最悪の場合システムが動かなくなってしまうことが予想されます。
なので、処理の構造や単位を理解し、「XXX毎に前処理できるのではないか」等の検討を経て細分化可能な処理の単位を見極めるべきです。処理の単位を細分化できれば、その単位で処理を並列実行すれば処理時間も早くなりますし、サーバーのリソースも効率的に活用できます。また多少パフォーマンスの悪いコードを書いても処理単位が小さければ大きな問題にはなりません。
3. 分析モデルのリファクタは必ず発生することを念頭に置く
検証段階ではJupyter Notebook等でインタラクティブに分析することが多く、そのままではシステムで動かすことはできません。
以下に起こりうる問題点と解決策をまとめました。
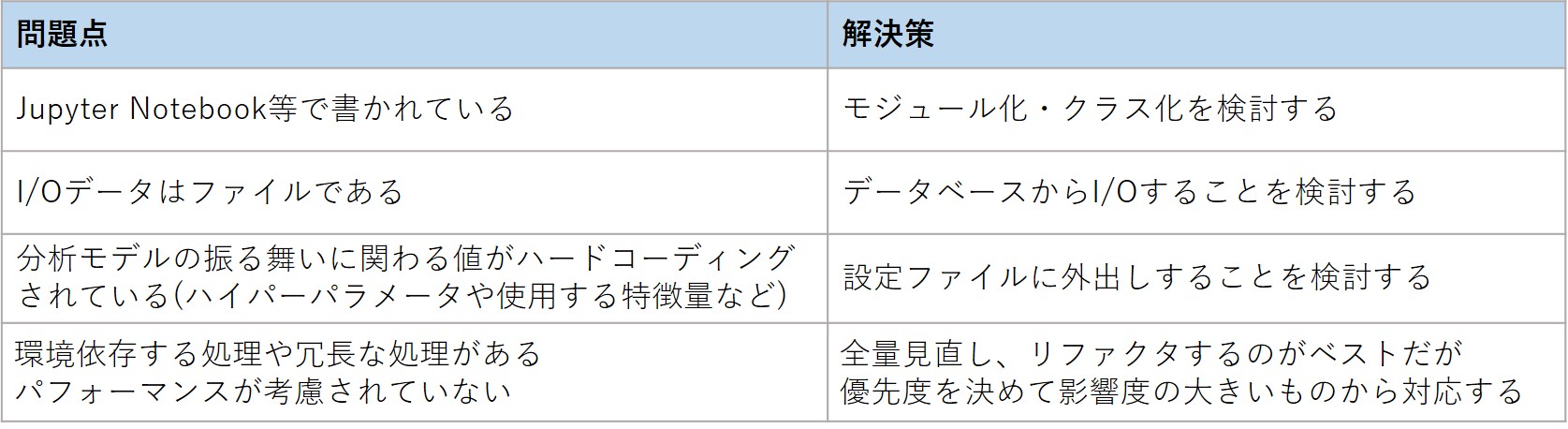
4. 異常系の考慮
検証フェーズでは分析に使用するデータで動けば良いので異常なデータが入力された場合の考慮をしないことが多いです。
システム化する際は以下の考慮が必要です。
- 不正なIFデータが入っている可能性はないか、入ってくる場合はどのような振る舞いをすべきか
- 入力データが0件の時にどのような振る舞いをすべきか
- 入力データはあるが、欠損が多く分析するのに不十分なデータ量の時にどのような振る舞いをすべきか
- 何らかの理由でモデルの学習ができなかった場合にどのような振る舞いをするか
上記はほんの一部ですが異常系の考慮はシステム開発する上で必要不可欠です。分析モデルもシステムの一部なので当然考慮すべきです。
5. 冪等(べきとう)性を担保する
商用運用する中で分析モデルが異常な振る舞いをした場合、開発環境等で再現確認する必要性が出てきます。 その時に完全に同一の現象を再現することができなかったら調査が困難になる場合があるので、冪等性を担保できる設計をすべきです。
具体的には以下について考慮する必要があります。
- 乱数を使用している場合はシードを固定する
- 使用しているパッケージ等のバージョンを固定する
- バックテストできるように学習時、予測時の情報をログ等で記録する
- I/Oデータ
- ハイパーパラメータ
- いつ時点のソースで動いたものか(GitのコミットIDなど)
おわりに
以上とさせて頂きます。全てにおいて上記が当てはまる訳ではないですが、分析モデルをシステムとして商用化する際にお役立て頂けると嬉しいです。
