取り組みの背景
ARISE analyticsの取り組みの一つに自然言語処理(NLP)技術を用いたテキスト分析があります。例えば、自由記述のアンケート(約10万件/月)を100以上のカテゴリに分類し分析するという案件が該当します。
NLPの分野では、2018年から転移学習の活用が進み、様々なNLPタスクにおいて精度の向上が報告されました。転移学習はあるデータセットで事前学習させたモデルを別のデータセットに転用する手法で、特に教師データ量が少ない状況で、精度向上を図るために用いられます。
ARISE analyticsが取り組む案件においても、テキスト用の教師データが大量に得られない状況が多いため、転移学習の効果を検証することになりました。しかし、日本語を扱える事前学習モデルはほとんど公開されていませんでした。
そこで、ARISE analyticsで日本語専用の事前学習モデルを構築し、転移学習の効果を確かめたうえで、モデルを公開することとしました。
アルゴリズム
ULMFiTの特徴
NLPに転移学習を活用するための手法として、ELMoやBERTなどいくつかの手法が2018年に発表されました。この中でARISE analyticsが試したのが、ULMFiT (Universal language model fine-tuning for text classification)です。この手法を採用した理由は下記のとおりです。
■ARISE analyticsの業務において、NLPに関するタスクはほとんどが分類タスクであったので、分類タスクに特化した手法で十分である
■BERTなどの手法に比べてモデルの作成に必要な計算リソースが少なくて済む
■教師データ量が少なくても精度が向上することが論文で明記されている
■開発者フォーラムにおいて、英語以外の言語でも精度向上が報告されていた
ULMFiTの概要
ULMFiTに関する解説記事はすでに日本語でも発表されており*¹、ARISE analyticsの論文読み会で取り上げた際の資料も公開しているため*²、ここでは概要の説明にとどめます。
アーキテクチャ
論文で使われたベースモデルはAWD-LSTMです。3層のLSTMを重ねた比較的単純なアーキテクチャを持ち、DropConnectを正則化に利用しています。今回の取り組みでは学習速度を向上させるためにLSTMの代わりにQRNNを用いました。
学習ステップ
学習ステップは下記の3つに分かれています。
■大規模コーパスを用いた事前学習
■分類したいテキストを用いたfine-tuning
■分類したいテキストを用いた分類モデル学習
事前学習
ULMFiTにおいて、事前学習 モデルを構築する際に与えるタスクは言語モデル構築です。つまり、入力として一続きの単語列をモデルに与えたときに、次の単語を予測することを目的としたタスクです。
興味深いのは、事前学習時のタスク(言語モデル構築)が転移後のタスク(分類)と異なる点です。画像分野では事前学習タスクと転移後のタスクが一致している場合が多いので対照的です。画像分野では、タスク別に大きな教師データセットが公開されているのですが、NLP分野、特に日本語も含めた英語以外の言語では、多くのタスクで大きな教師データセットが公開されていません。
しかしながら、言語モデル構築タスクは教師ラベルを付ける必要が無いので、大量のテキストさえあれば容易にデータセットを作成できます。ULMFiTだけでなく、ELMo、BERTといった手法は、いずれも言語モデル構築タスクを通じてモデルに言語の特徴を学習させ、他のタスクに転移することで精度向上を図っています。
では、ULMFiTの事前学習で得られるもの(モデルの表現)と、word2vecなどのword embeddingベクトルとの違いは何でしょうか?
共通点としては、学習に教師ラベルのないテキストを用いる点と、学習結果を学習時と異なるタスクに転用する点が挙げられます。異なるのは、得られた結果が語順や文脈を反映しているかどうか、という点です。ある単語に対応するword embeddingベクトルは語順や文脈に依存しませんが、ある単語を入力した際にULMFiT事前学習モデルが出力するベクトルは、事前に入力した単語の列、つまり語順や文脈に依存します。
このように、word embeddingに比べて、語順や文脈といった高次の特徴まで含めた表現を転用できるようになったことが、NLP分野の大きなブレークスルーとなりました。
なお、論文では英語のWikipediaダンプを用いて事前学習を実施していましたが、今回の取り組みでは日本語Wikipediaのダンプを用いました。
Fine-tuning
このステップは、分類したいテキストを使って、事前学習済みの言語モデルを微調整するステップです。このステップによって、その後の分類精度が向上することが論文で示されています。学習率を層ごと、イテレーションごとに変化させることで効果を高めています。
分類モデル学習
Fine-tuning済みのモデルに分類用の層を付加して、分類モデルとして学習させるステップです。上記2ステップで学習したことを忘れすぎないように、出力層に近い層から順に解凍する手法を用いています。
日本語への適用
データセットと分類タスク
NTCIR-13 MedWeb*³
NTCIR (NII Testbeds and Community for Information access Research)が公開しているマルチラベル分類タスクのデータセットです。データセットの説明をNTCIRのサイトから引用します。
NTCIR-13 MedWeb では、任意のツイートに対して、8つの病気または症状(インフルエンザ、下痢/腹痛、花粉症、咳/喉の痛み、頭痛、熱、鼻水/鼻づまり、風邪)の罹患の有無を割り当てるマルチラベル分類タスクを実施いたしました。
下記の論文では、タスクの詳細だけでなく、このデータセットを使って実施された分類コンペの成績も載っています。
Shoko Wakamiya, Mizuki Morita, Yoshinobu Kano, Tomoko Ohkuma and Eiji Aramaki: Overview of the NTCIR-13 MedWeb Task, In Proceedings of the 13th NTCIR Conference on Evaluation of Information Access Technologies (NTCIR-13), pp. 40-49, 2017.
青空文庫
青空文庫の中から、5人の著者(夏目漱石、芥川龍之介など)の著作物を抽出し、データセットを作成しました。タスクとしては、1文ごとに著者を推定するマルチクラス分類となります。このページ*⁴を参考にさせていただきました。
トークン化処理
日本語は文中で単語と単語がスペースで区切られていないため、言語モデル構築の前処理として文をトークンに分割することが必要です。分割ソフトウェアとしてはMeCabなど、辞書を用いたものがよく使われますが、今回はSentencepiece*⁵というパッケージを利用しました。
このパッケージは辞書を必要とせず、テキストから直接分割を学習する手法を採用しています。この手法を使うと、未知語をほぼゼロに抑えたまま語彙数を小さくすることができます。言語モデル構築は文中の次の語を予測するタスクですので、語彙数が小さいほうが学習しやすいのではないか、と考えたのがSentencepieceを利用した理由です。
分類精度
日本語のデータセットにULMFiTを適用して分類精度を検証しました。観点としては、SOTAが得られたか、ではなく、教師データガ少ない場合に事前学習によってどれほど精度が向上するのか、という点に着目しました。以下にデータセットごとの成績を記します。
NTCIR-13 MedWebN
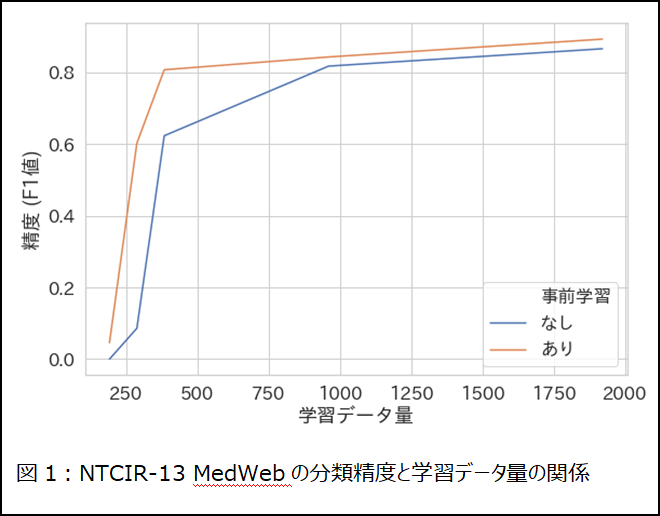
教師データ量と分類精度(F1 micro)の関係を表したグラフ(図1)からわかるように、特に教師データ量が少ない状況で事前学習による精度向上の幅が大きかったです。400件弱の教師データ量でも、事前学習をすることで、1000件弱の教師データ量を用いて事前学習なしの場合と同等の精度が得られました。この結果を鑑みると、ULMFiTは実務における教師データ作成工数の削減に大きく寄与すると言えます。
ちなみに、フルデータセットを用いて得られた精度(F1=0.893)はSOTA(F1=0.920)に及ばなかったのですが、論文中のリーダーボードで21チーム中4位に相当する成績でした。あまりチューニングに工数をかけずにこの精度に達することができたので、他の手法と比べてもULMFiT、ならびにベースとなるアーキテクチャは競争力を持った手法だと言えます。
青空文庫
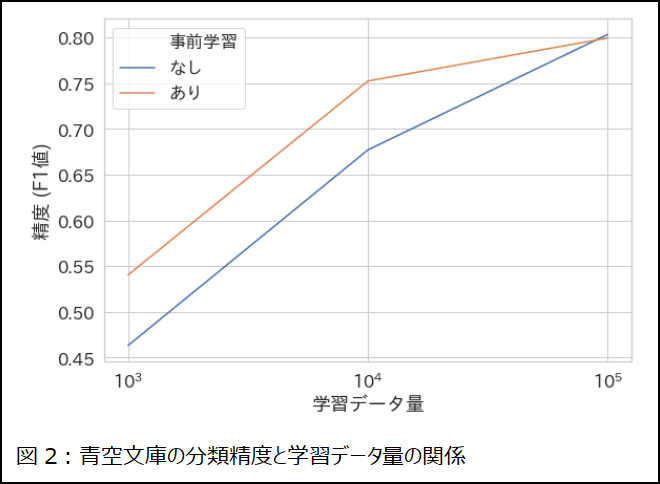
こちらのタスクでも、教師データが少ない状況で事前学習の効果が高いことが認められました(図2)。ただし、教師データ量が十分にあれば、事前学習による精度差はなくなることも確かめられました。
コードとモデルの公開
今回の取り組みにあたっては、ULMFiTの開発チームであるfast.aiが運営するフォーラム*⁶から多くの情報を頂きました。そのフォーラムでULMFiTを英語以外の言語に適用することを目的としたレポジトリ*⁷が公開されていることを知りました。ARISE analyticsは、このレポジトリをforkした上で、トークン化処理プログラムを変更し、上記日本語データセットを検証するためのスクリプトを追加しました。コードと事前学習済みの日本語言語モデルをこちら*⁸ *⁹に公開しましたので、ご興味のある方はぜひご利用ください。
まとめ
■日本語テキスト分類タスクにおいて、教師データ作成工数を削減することを目的として、ULMFiTの効果を検証した
■その結果、ULMFiTによって少ない教師データ量でも分類精度が向上することが明らかになった
■ULMFiTを日本語テキストに適用するためのコードとモデルを一般公開した
<参照リンク>
*¹https://qiita.com/kogecoo/items/49dd9019bf9268bd8e38
*²https://www.slideshare.net/ARISEanalytics/universal-language-model-finetuning-for-text-classification
*³http://research.nii.ac.jp/ntcir/permission/ntcir-13/perm-ja-MedWeb.html
*⁴https://qiita.com/cvusk/items/c1342dd0fff16dc37ddf
*⁵https://qiita.com/taku910/items/7e52f1e58d0ea6e7859c
*⁶https://forums.fast.ai/t/multilingual-ulmfit/28117
*⁷https://github.com/n-waves/ulmfit-multilingual
*⁸コード:https://github.com/tsurushun/ulmfit-multilingual/tree/japanese
*⁹モデル:https://drive.google.com/open?id=1op2Ex2FgBx7JB0Ld4tKDWH_LQ8HUPrq5