ARISE analyticsでは工場設備の予防保全ソリューション「ARISE Predictive Maintenance」を提供しています。このソリューションは、機械学習を用いて機器の故障に繋がると思われる軽微な異常を予兆として検出することで工場設備の予防保全を可能にします。異常検知を実際のデータに対して適用するためには、様々なポイントがあります。この記事では、そうしたポイントと関連する技術について紹介いたします。
ARISE Predictive Maintenanceとは
工場設備のデータをクラウド上に収集・蓄積し、異常に繋がる予兆を機械学習で検出するソリューションです。本ソリューションは、KDDIが提供するKDDI IoTクラウド 工場パッケージのオプションとして、顧客に対して異常検知機能を提供致します
分析対象となるデータは、工場設備に設置したセンサーおよび機器制御データ(PLC)から収集します。本ソリューションが提供する機械学習アルゴリズムは、特定の生産設備やセンサーの種類に依存しないため、既存の設備に必要なセンサーを追加して利用することができます。センサーの種類は各工場設備の特性を考慮して選定されますが、一般的に振動・温度・電流などのセンサーが用いられます。こうしたセンサーから異常検知を行う際、センサー単体の挙動から異常を発見するだけでなく、複数のセンサーデータや機器制御データの関連性を考慮した異常検知にも対応しております。
収集したデータや機器の状態は、ダッシュボードを利用することでほぼリアルタイムに確認することができます。また、実際に予兆につながりうる異常が発生した場合には、あらかじめ設定した通知先に対してメールや機械音声の電話にて通知が行われるため、ユーザーは機器の異常状態を素早く把握することが可能です。
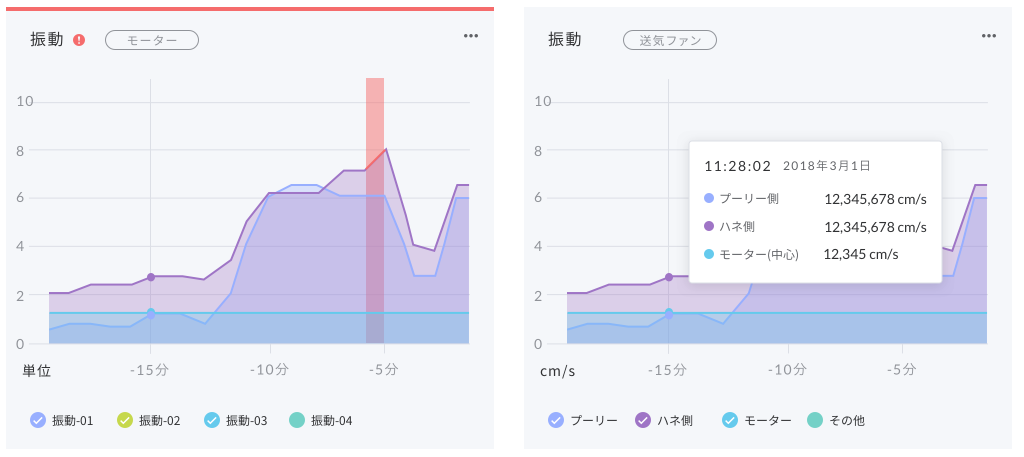
本ソリューションは導入企業に対し、主に以下の効果の提供が可能です。
- 重大故障の防止(修繕コスト削減)
- 工場設備の状況を遠隔で常時監視できるため、日々発生する人手での点検工数を削減。更に機器状態に合わせて、部品の交換時期を見直すことで、不要なメンテナンス費用を低減します。
- 生産の安定化
- 機械の誤動作により発生する製品品質の悪化を防止し、品質及び生産の安定化を図ることが可能です。
- 点検工数の削減
- 異常につながりうる軽微な予兆がみられた場合に、あらかじめ点検や部品交換を行うことで、工場の突発的な停止を予防し、定期点検時の点検工数の削減が実現できます。
しかしながら、多くの工場ではデータ分析によって機器予防保全を行おうと考えても、故障はまれにしか発生しないため分析に使えるデータを蓄積することが難しい、そもそもデータを扱うことのできるデータサイエンティストが社内にいない、等の課題があります。そこで本ソリューションでは、そうした工場でも活用できるよう以下の特徴を備えています。
- 故障データのサンプル無しで、定常状態のデータから故障の予測モデルを構築可能
- 故障状態を含んだデータが長期間蓄積されていなくとも、定常状態のデータを用いた教師無し学習によって故障の予測モデルを構築可能です。また、特徴抽出アルゴリズムを活用することで、より多くのパターンの故障を予測することが出来ます。
- 予測モデルの検知精度を継続的に向上
- ユーザーは故障状態と推定された場合に送信されるアラートに対して、実際に故障だったかどうかの確認結果をダッシュボードから入力します。本ソリューションはそのフィードバックを元に予測モデルを更新し、データサイエンティストがいなくても故障検知の精度を継続的に向上させていくことができます
ソリューション実現のために
顧客により、工場の規模や設置されるセンサー、ネットワーク接続状況はさまざまであり、ソリューションを実現させる過程において下記の側面を考慮する必要があります。
- 受信データ量: センサーは生産設備の構成要素に対して複数設置される場合が多く、大量のデータを処理する必要がある。例えば、一台のモーターに両側の軸受と本体など複数の振動計を設置する場合がある
- 受信フォーマットの差異: ロガーや接続先のシステムにより、送信されるデータのフォーマットが異なる
- 受信間隔のずれ: 工場との通信状況によりデータの受信が遅れる場合がある。また、ロガーとの時刻のずれにより、ログ中のタイムスタンプも一定間隔とならない場合がある
また、異常検知処理においても工場の特性に応じた処理を行う必要があり、下記の側面を考慮しなければなりません。
- 稼動状態の考慮: 工場の稼動は一定ではないため、単一のアルゴリズムは使えない。例えば、電源を投入した結果発生する振動は異常として検知すべきではない
- 多様な異常の検知: 監視すべき機器は工場によって異なる。また、検知したい異常の種類(振動の大きさ、振動のパターンの変化)も設備の特性によって異なる
- 異常データの判定: データ上は異常に見える場合でも、工場のオペレーション起因など実際には異常でない場合がある
これら考慮すべきポイントを踏まえた上で構築されたアーキテクチャ・分析アルゴリズムについて、以下で具体的に記載していきます。
アーキテクチャ
異常検知処理を行う分析エンジン、ならびにユーザー向けのダッシュボードはAWS上に構築されています。工場設備のデータはネットワークを介してAWS上に構築された分析エンジンに送られ、異常検知処理が行われます。
アーキテクチャは以下の3つに分けられます。
- データ蓄積: 工場設備のデータを受信し、蓄積する (API Gateway, AWS Lambda, Dynamo DB)
- 分析: 異常検知アルゴリズムを定期的に実行する (分析サーバ)
- 可視化、通知: ユーザー向けのダッシュボードを提供し、ユーザーへの通知を行う (Web/APサーバ)
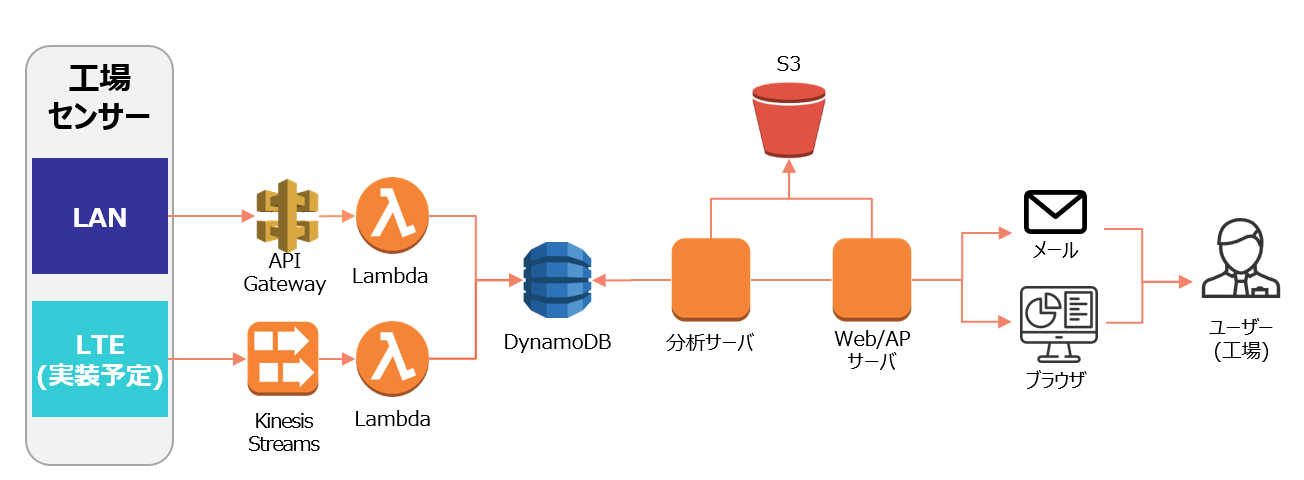
大量に送信されるデータを処理するため、サーバーレス構成を用いてスケールアウト可能な構成としています。接続先のシステムによっては、送信されてくるデータのフォーマットが異なる場合があります。その差異を吸収するため、 AWS Lambda を用いて共通の蓄積フォーマットへ変換した上で Dynamo DBへ保存します。現時点ではLANを介してAWSへデータをアップロードしていますが、より簡便な選択肢としてLTEを介した手法も実装予定です。
分析サーバは定期的に収集・蓄積されたデータを用いて異常検知モデルを学習させます。常に適切な異常検知処理を行うため、異常検知モデルは定期的に一定区間のデータを用いて更新されます。この時、分析サーバではデータの微妙なタイムスタンプのずれの補正や、欠損値の補完など、学習にあたって必要な前処理も行っています。学習した異常検知モデルは、再現性の担保のためそれぞれ適切にバージョンを付与してS3に保存されます。
こうして定期的に学習した異常検知モデルを用いて、ほぼリアルタイムで異常検知処理(推論処理)を行います(後述)。
分析サーバがなんらかの異常を検知すると、Web/APサーバを経由してユーザーへ通知を送信します。また、新たなデータが蓄積されるとWebサーバ上のダッシュボードがほぼリアルタイムで更新されます。Webサーバでは XSSやSQL injectionsなど一般的なセキュリティ対策を行っています。全ての通信は暗号化した上で行われます。
分析アルゴリズム
異常検知処理はいくつかのステップにより実行されます。流れとしては以下のようになります。
- 稼動状態の推定: 時系列データを元に機器の稼働状態を予測し、稼動状態ごとに分割する
- 時系列特徴の推定: 分割した時系列データごとに特徴を判別する
- 異常検知アルゴリズムの実行: 時系列的な特徴と異常検知対象とするパターンに応じて機械学習モデルを実行する
機械学習モデルは複数の学習アルゴリズムから適切なものが選択されます。その際のハイパーパラメータ調整にユーザーからのフィードバック(後述)を用いることで、継続的な精度向上を実現します
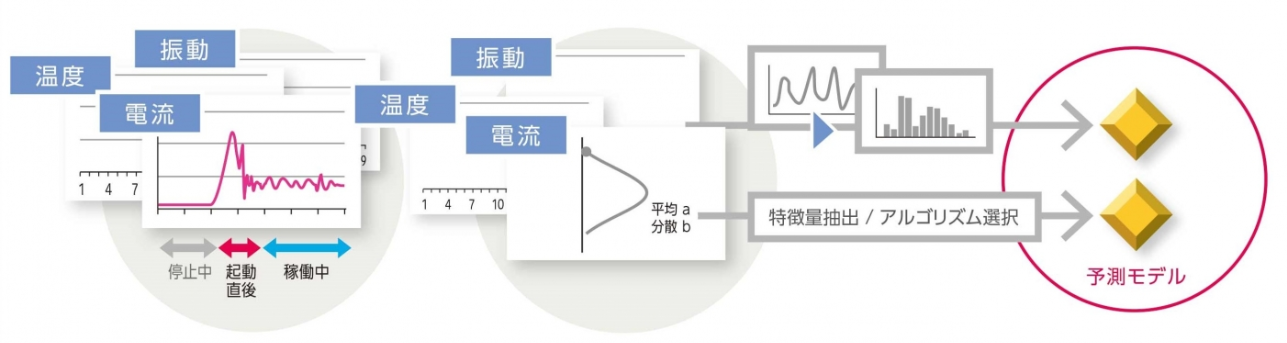
稼動状態の推定
機器の稼働状態をモデルにより予測します。工場の機器は、例えば稼働中と停止中で挙動が大きく異なるため、これらを区別してデータ分析を行うためです。モデルとしてはルールベースや教師なし学習(e.g. クラスタリング、状態空間モデル)が適用されています。
具体的な稼働状態の判別結果としては、上図の電流値のグラフが例として挙げられます。挙動が大きく異なるため、稼働中と停止中の稼働状態判別を行います。また起動直後は安定稼働中と比べて値が大きいなど挙動が異なる場合があるため、起動直後と稼働中の状態判別も行います。
以降の処理は、ここで判別した稼動状態ごとに分割した時系列データごとに行われます。
時系列特徴の推定
時系列データの特徴を判別します。機械学習モデルによっては、入力となるデータに様々な前提条件があります。時系列データの特徴を判別することで、適切なモデルの選択に利用します。
具体的には、データの自己相関、定常性、分布、トレンドや季節性の有無などを統計学的に検定します。また、これらの判別結果をもとに適切な変数変換を前処理として実行し、特徴量を生成します。
(時系列特徴推定例):自己相関検定
対象の時系列データが自己相関を持つかを、自己相関を持たないという帰無仮説に基づいたLjung-Box testにより検定します。Ljung-Box統計量は下式で表され、\(n\)は標本数、\(\hat{\rho}\)は時間差\(j\)における標本自己相関、\(h\)は検定する時間差の数を表します。
$$Q = n(n+2)\sum^h_{k=1}\frac{\hat{\rho}^2_k}{n-k}$$
統計量\(Q\)は自由度\(h\)のカイ二乗分布に従うため、有意水準\(\alpha\)において下条件により帰無仮説が棄却され、対象時系列データは自己相関を持たないとはいえないという結果が導かれます。
$$Q > \chi^2_{1-\alpha, h}$$
異常検知アルゴリズムの実行
入力となる時系列の特徴と異常検知対象とするパターンに応じて、適切な異常検知アルゴリズムを実行します。
異常検知対象とするパターンとして、時系列データがどのような傾向を示した場合に異常とみなすかをあらかじめ設定しておきます。
監視する工場設備が多様なこと、また、検知したい異常の種類も設備の特性によって異なることから、多様な状況に対応できるような設定を可能にしています。
以下に、異常検知対象パターンとして対応している例を列挙します。
- 外れ値:
- ある一時点のデータが、他の値と比較して明らかに外れた値となった場合
- 変化点
- データのレベル(平均)やばらつき(分散)がある時点を境に変化した場合
- 時系列予測モデルとの乖離
- 過去のデータから将来を予測する時系列モデルを構築しておき、記録された値がその予測から大きく外れた場合
- 相関関係の変化
- 2つ以上のデータの組の相関関係が変化した場合
- 周波数の変化
- ある時点を境にデータの周波数成分が変化した場合
- 統計的分布の変化
- ある時点を境にデータの統計的分布が変化した場合
- トレンド・季節性の変化
- ある時点を境にデータのトレンド・季節性が変化した場合
具体的にはホテリングの\(T^2\)法やLocal Outlier Factorなどといった外れ値検知、累積和法などの変化点検知、ARIMAモデルやKalman Filterなどといった時系列予測モデルからの乖離検知、Pearsonの相関係数を用いた相関関係変化検知、FFTを用いた周波数の変化検知、統計的検定を用いたトレンド・季節性の変化検知などが挙げられます。
(アルゴリズム選択例):データに季節性が含まれる場合
- 季節性の変化検知が対象パターンに含まれている際、時系列データが単変量、非定常過程、季節性ありと判定された場合には季節性の変化検知アルゴリズムが適用されます
- 外れ値が対象パターンに含まれている際、時系列データが多変量の場合にはホテリングの\(T^2\)法やLocal Outlier Factorなどの外れ値検知アルゴリズムが適用されます
(異常検知アルゴリズム例):ホテリングの\(T^2\)法
データが多変量正規分布に従う場合に外れ値を検知する手法です。データが\(M\)次元正規分布\(N(\mu,\Sigma)\)に従い、\(N\)個の独立標本に基づいた標本平均\(\hat{\mu}\)、標本分散\(\hat{\Sigma}\)とし、独立標本は\(x’\)で表されるとすると、共分散を考慮した\(x’\)と\(\hat{\mu}\)の距離であるマハラノビス距離は下式で表されます。
$$a(x’) = \sqrt{(x’-\hat{\mu})^{T}\hat{\Sigma}^{-1}(x’-\hat{\mu})}$$
このとき下式で定義されるホテリング統計量\(T^2\)は自由度(\(M,N-M\))のF分布に従います。
$$T^2 = \frac{N-M}{(N+1)M}a^2(x’)$$
ここで\(N \gg M\)の場合(通常この場合に当てはまる)、\(a^2(x’)\)は近似的に自由度\(M\)、スケール因子1のカイ二乗分布に従います。よって有意水準\(\alpha\)において下条件を満たす場合に独立標本\(x’\)は外れ値と判定されます。
$$a^2(x’) > \chi^2_{1-\alpha, M}$$
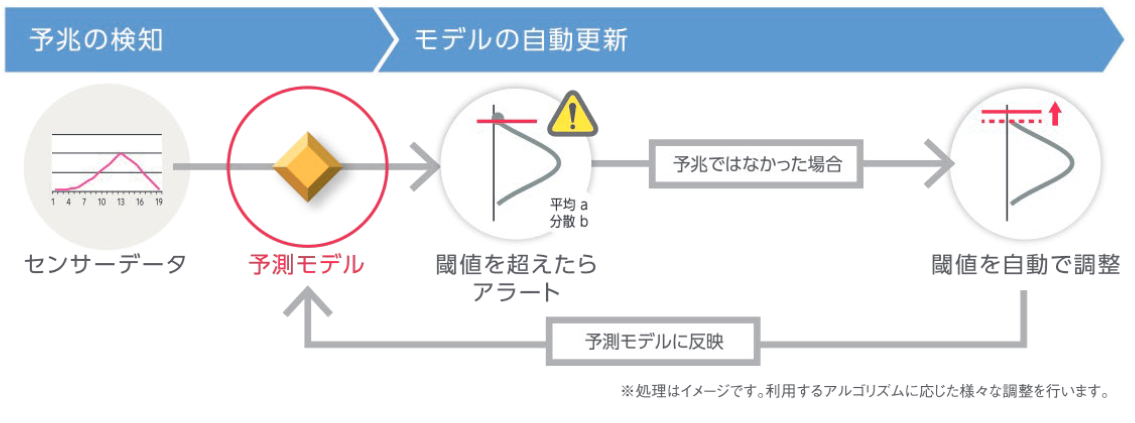
ユーザーフィードバックによる再学習
工場においては、データ上は異常に見える場合でも、工場のオペレーション起因など実際には異常でない場合があります。こうした誤検知を削減するため、本ソリューションではユーザーのフィードバックにもとづいて再学習を行っています。このようにしてモデルを各工場へ最適化していくことで、継続的な精度向上を目指しています。
再学習は以下のタイミングで行われます。
- ソリューションからアラートが送信されたが、ユーザーからは「異常なし」のフィードバックが入力された
- ソリューションからはアラートが送信されていないが、ユーザーから「異常あり」のフィードバックが入力された
再学習処理では、過去のアラートとフィードバックの履歴を元に教師なし学習のハイパーパラメータを調整し、モデルを再学習させることで実現しています。調整に際しては\(F_{\beta}\)値を基準に用い、各々の工場のオペレーションに応じて適合率を優先する場合(上記1のケースを減らしたい場合)、再現率を優先する場合(上記2のケースを減らしたい場合)に対応します。
まとめ
本記事では、工場運営における課題解決ソリューション「ARISE Predictive Maintenance」をご紹介いたしました。ARISE analyticsは今後も最新のアルゴリズムを適宜導入することにより、「ARISE Predictive Maintenance」の継続的な性能向上に努めていくとともに、様々な業界の課題を解決するソリューションの開発に邁進して参ります。
参考文献
- 異常検知と変化検知(井出剛、杉山将)
- 経済・ファイナンスデータの計量時系列分析(沖本竜義)
- 入門機械学習による異常検知(井出剛)