はじめに
ARISE analyticsの近藤です。
弊社では、KDDIグループを支えるためのAI技術開発を行っています。その一環でプロダクト開発を目的とした研究開発も進めています。
AIを活用したプロダクトとして、RPA(Robotic Process Automation)などが挙げられます。RPAでは大量のデータを短時間で処理する必要があります。そのため、AIの性能に加え処理速度も重視されます。また、AWSやAzure等のクラウド上で処理する場合は、インスタンスコストを削減するため可能な限りスペックを抑制する必要があります。
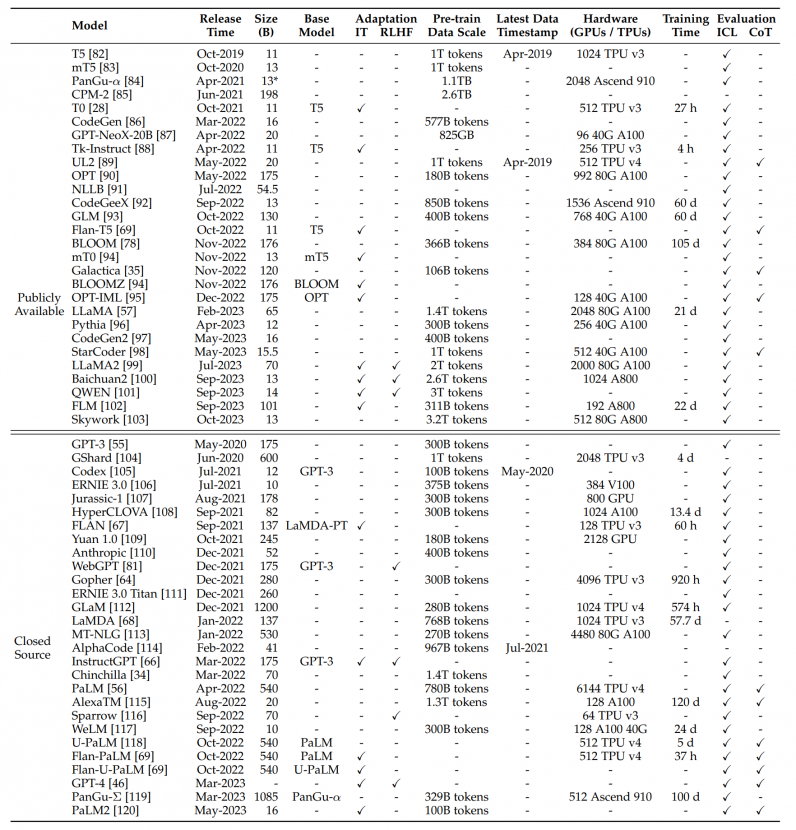
とくにスペック抑制に関しては、近年普及が進んでいるLLM(Large Language Model)で重視されています。パラメタ数はLLMの性能に影響を及ぼす重要なファクタですが、パラメタ数が大きくなるほど必要とするGPUのスペックも高くなります。具体的には、モデルサイズはパラメタ数×4バイト(パラメタ1つにつき32bitの浮動小数点、すなわち4byteで表現した場合)で表されるため、同等以上のGPUメモリを必要とします。例えば、表1ではGPT-3は175B(1750億)のパラメタを持つため、モデルサイズは7000億byte(651.93GB)となります。このようなモデルを読み込むためには、NVIDIA A100 80GBが9台必要になる計算となります。このスペックを用意しようとすると、かなりの高コストになることが予想されます。
表1:2023年10月時点の代表的な大規模言語モデルの情報(引用:A Survey of Large Language Models)
DeepSpeedの概要を知ろう
DeepSpeedはMicrosoftが開発した深層学習向け高速化・省メモリ化ライブラリです。深層学習のボトルネックである計算量・メモリ量・データ量の扱いを解決するための機能が多数盛り込まれており、近年著しい発展を遂げている拡散モデルやLLMのような生成AIの処理高速化にも活用されています。
DeepSpeedの特徴として、以下が挙げられます。
- 数十億~1兆規模のパラメタを持つ超巨大な深層学習モデルの訓練と推論
- GPU間のデータ転送が高速かつ低遅延
- 数千GPU規模のスケーラビリティの訓練
- 限られたGPUリソース環境における訓練と推論
- モデル圧縮技術による低遅延な推論、モデルサイズ削減機能
いずれも、計算量・メモリ量・データ量の高効率な処理を実現するものです。
上記の処理は深層学習(ニューラルネットワーク)を用いた処理に対して汎用的に適用可能であり、生成AIのみならずTransformerや畳み込みニューラルネットワーク、グラフニューラルネットワーク等極めて広い範囲に適用可能です。また、公式の日本語のサポートも非常に手厚く、公式X、公式ブログといった発信が行われていることに加え、日本語での問い合わせも可能という厚遇っぷりです。
DeepSpeedには深層学習の課題に合わせた機能が複数用意されています。一部をピックアップして紹介します(日本語の解説資料も存在するため、詳細はそちらをご覧ください)。
表2:課題に対するDeepSpeedの機能一覧(DeepSpeed: 深層学習の訓練と推論を劇的に 高速化するフレームワークを基に改編)
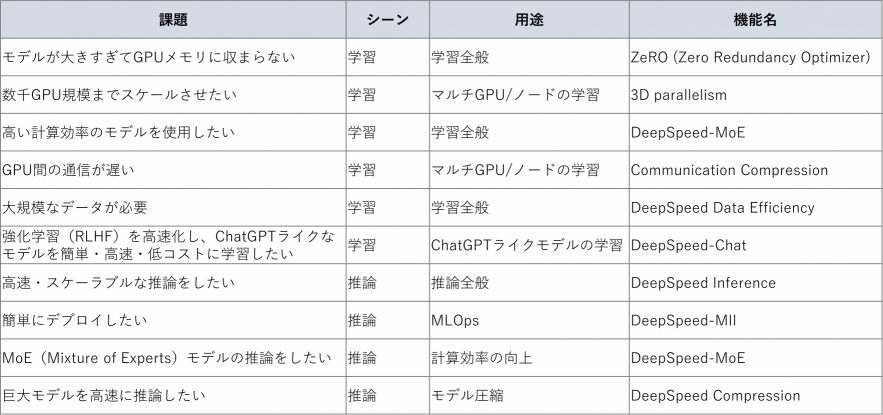
モデル推論を高速化するために DeepSpeed Compressionを用いてモデル圧縮を行う、ChatGPTライクなモデルを作るためにDeepSpeed-Chatを用いてより高速な強化学習を実現する、数千GPUで学習を行うために3D parallelismを用いる、といった使い方が可能であり、大規模な学習を行う上で必須のツールと言えるでしょう。
このうち、DeepSpeedの一番の特徴といわれるのがZeRO(Zero Redundancy Optimizer)です。
パラメタ数が大きいLLMを学習する場合、単体のGPUではモデルがGPUメモリに乗りきらないため、複数のGPUを用いることが不可欠です。複数GPUを用いる場合、モデル全体を各GPUに読み込ませたうえで処理するのが一般的ですが、ZeROでは必要なパラメタだけ読み込ませて処理する、という工夫を行っています。これにより、メモリ利用の効率化に成功しています。
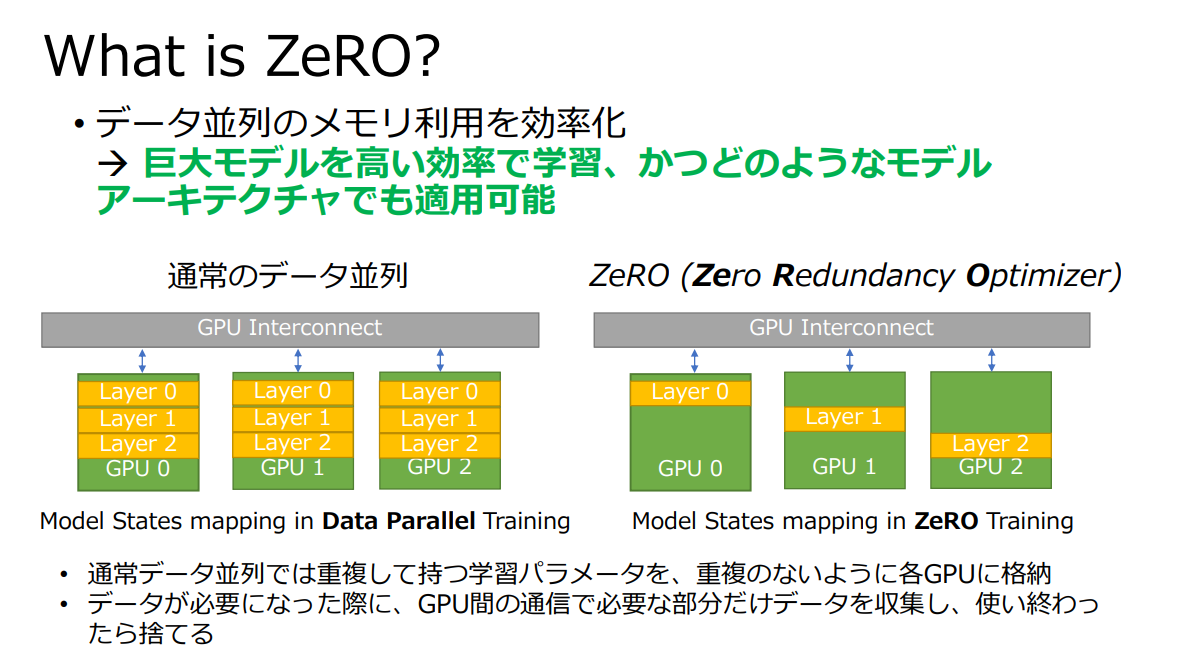
図1:2023年10月時点の代表的な大規模言語モデルの情報(引用:DeepSpeed: 深層学習の訓練と推論を劇的に 高速化するフレームワーク)
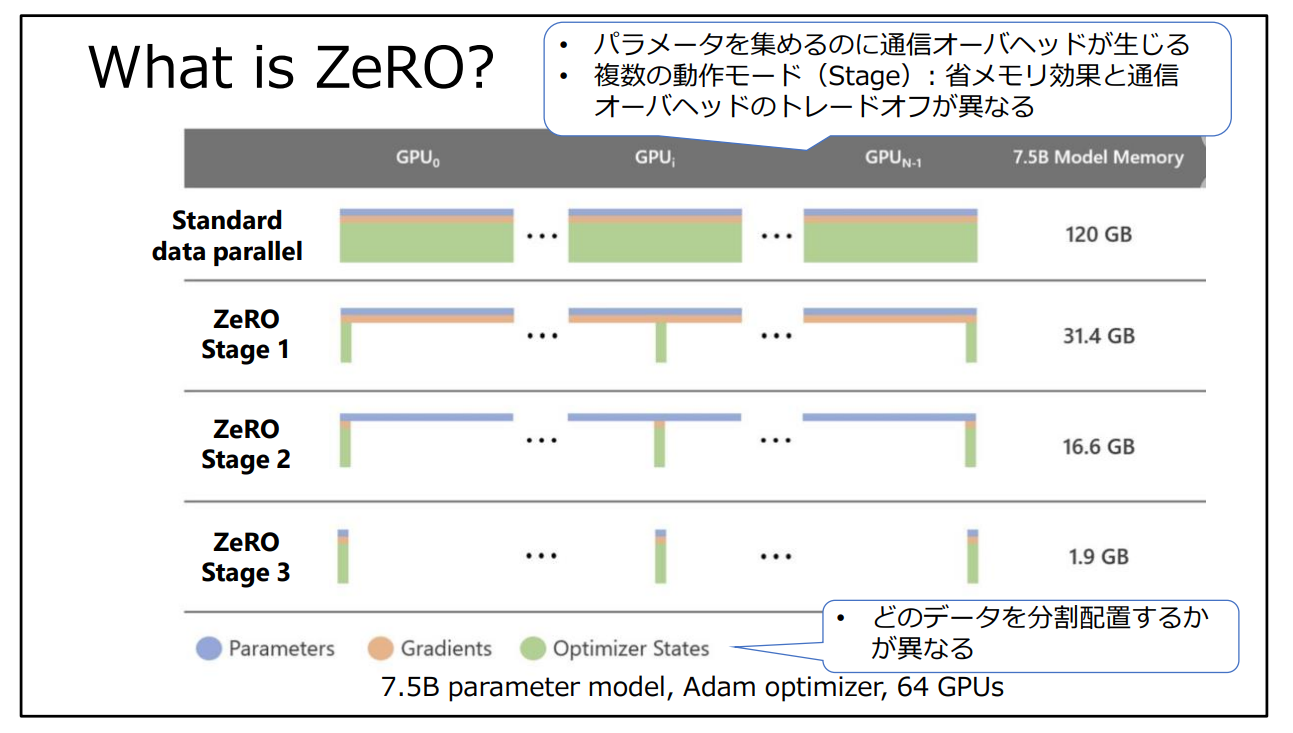
図2:2023年10月時点の代表的な大規模言語モデルの情報(引用:DeepSpeed: 深層学習の訓練と推論を劇的に 高速化するフレームワーク)
メモリ効率化を行うという考え方は、ZeROファミリーに共通する考え方です。ZeRO-Offloadでは、複数GPUを持たないケースにおいても、CPUメモリにオフロード(負荷分散)するアイデアにより40B(400億)パラメタのモデルを単体GPUで学習することに成功しています。
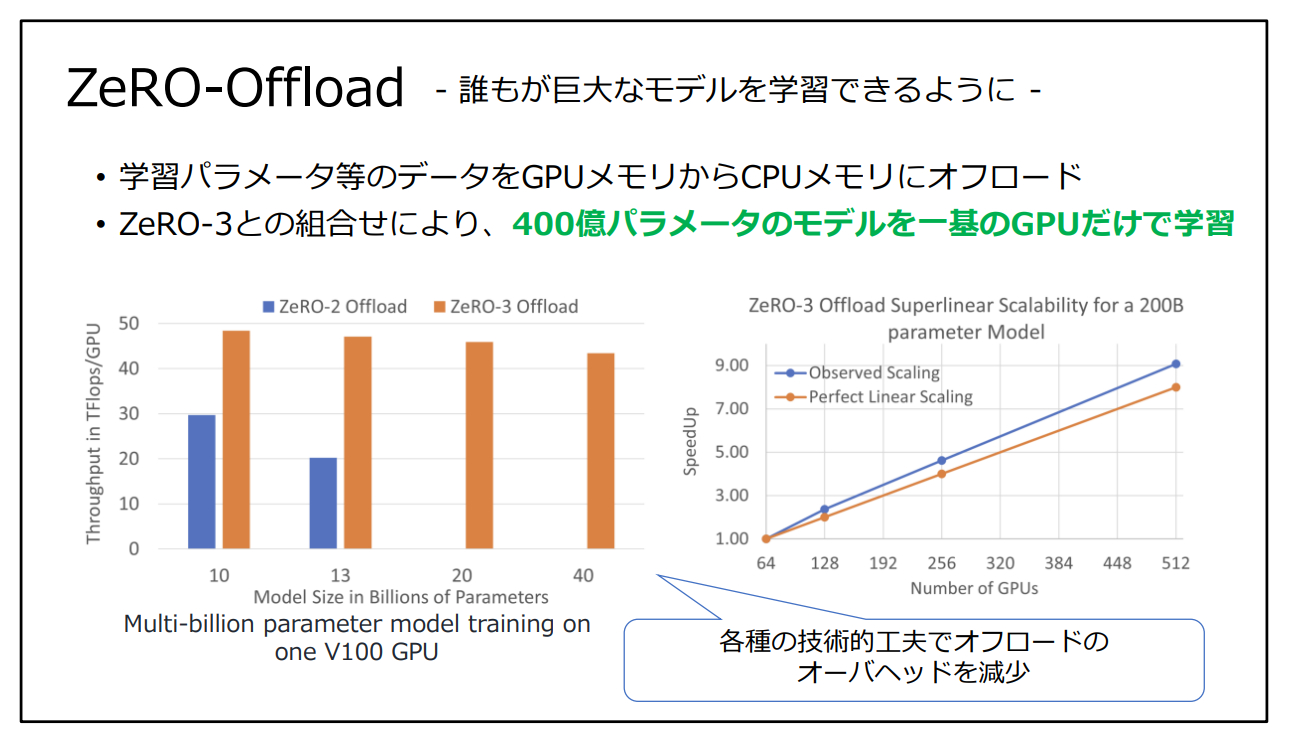
図3:2023年10月時点の代表的な大規模言語モデルの情報(引用:DeepSpeed: 深層学習の訓練と推論を劇的に 高速化するフレームワーク)
DeepSpeedを動かしてみよう
ここまでDeepSpeedの概要と機能を紹介しました。ここからは、実際にDeepSpeedを動かしてみることで、具体的な性能を確認していきます。
セットアップ
検証に用いた環境(オンプレ)を以下に示します。

今回は、transformersに搭載されているdeepspeedのサンプルを用いて測定を行います。インストールは以下コマンドで実行できます。詳細は、DeepSpeed Integrationをご参照ください。
pip install deepspeed sacrebleu numactl datasets
git clone https://github.com/huggingface/transformers
cd transformers
pip install .DeepSpeedの設定はjsonファイルを用いて記述します。今回用いた設定ファイルは以下の通りです。
ds_config_zero2.json
{
"fp16":{
"enabled":"auto",
"loss_scale":0,
"loss_scale_window":1000,
"initial_scale_power":16,
"hysteresis":2,
"min_loss_scale":1
},
"bf16":{
"enabled":"auto"
},
"optimizer":{
"type":"AdamW",
"params":{
"lr":"auto",
"betas":"auto",
"eps":"auto",
"weight_decay":"auto"
}
},
"scheduler":{
"type":"WarmupLR",
"params":{
"warmup_min_lr":"auto",
"warmup_max_lr":"auto",
"warmup_num_steps":"auto"
}
},
"zero_optimization":{
"stage":2,
"offload_optimizer":{
"device":"cpu",
"pin_memory":true
},
"allgather_partitions":true,
"allgather_bucket_size":2e8,
"overlap_comm":true,
"reduce_scatter":true,
"reduce_bucket_size":2e8,
"contiguous_gradients":true
},
"gradient_accumulation_steps":"auto",
"gradient_clipping":"auto",
"steps_per_print":2000,
"train_batch_size":"auto",
"train_micro_batch_size_per_gpu":"auto",
"wall_clock_breakdown":false
}実験
今回は2種類の実験を行います。
- 単体GPUでの測定(ZeRO Offload)
- 複数GPUでの測定(ZeRO Stage-2)
問題設定として、サンプルとして公開されているtransformersを用いた2言語間の翻訳タスク(英語→ロシア語)におけるファインチューニングを適用します。実験にあたっての具体的なパラメタは、実行コマンドの引数をご参照ください。今回は、ベースモデル、およびバッチサイズを変更しながら、DeepSpeedを用いた場合と用いない場合のCPU使用率・GPUメモリ使用量・訓練の所要時間を測定します。
(簡易な測定のため、測定値は誤差が生じている可能性があります)
実行コマンド
測定①:単体GPUでの測定(ZeRO Offload)
本測定では、単体GPUを用いて測定します。具体的には、以下のコマンドを用いて実行します。
共通
git clone https://github.com/huggingface/transformers
cd transformersDeepSpeed適用なしの実行コマンド
CUDA_VISIBLE_DEVICES=1 python examples/pytorch/translation/run_translation.py \
--model_name_or_path ${BASE_MODEL} --per_device_train_batch_size ${BATCH_SIZE}\
--output_dir ~/output_dir --overwrite_output_dir --fp16 \
--do_train --max_train_samples 10000 --num_train_epochs 1\
--dataset_name wmt16 --dataset_config "ro-en"\
--source_lang en --target_lang roDeepSpeed(ZeRO Offload)適用ありの実行コマンド
deepspeed --include localhost:1 examples/pytorch/translation/run_translation.py \
--deepspeed ds_config_zero2.json \
--model_name_or_path ${BASE_MODEL} --per_device_train_batch_size ${BATCH_SIZE}\
--output_dir ~/output_dir --overwrite_output_dir --fp16 \
--do_train --max_train_samples 10000 --num_train_epochs 1\
--dataset_name wmt16 --dataset_config "ro-en"\
--source_lang en --target_lang roDeepSpeedを用いない場合は、CUDA_VISIBLE_DEVICESでGPUを指定しますが、DeepSpeedでGPUを指定する場合は、–include localhost:1 (ホスト名:GPUのデバイス番号)を指定することにご注意ください(デバイス数だけ指定する場合は、–num_gpus=1で指定できます)。
${BASE_MODEL} はt5-smallとt5-baseを、${BATCH_SIZE} は2^0から2^8を用いました。
測定結果
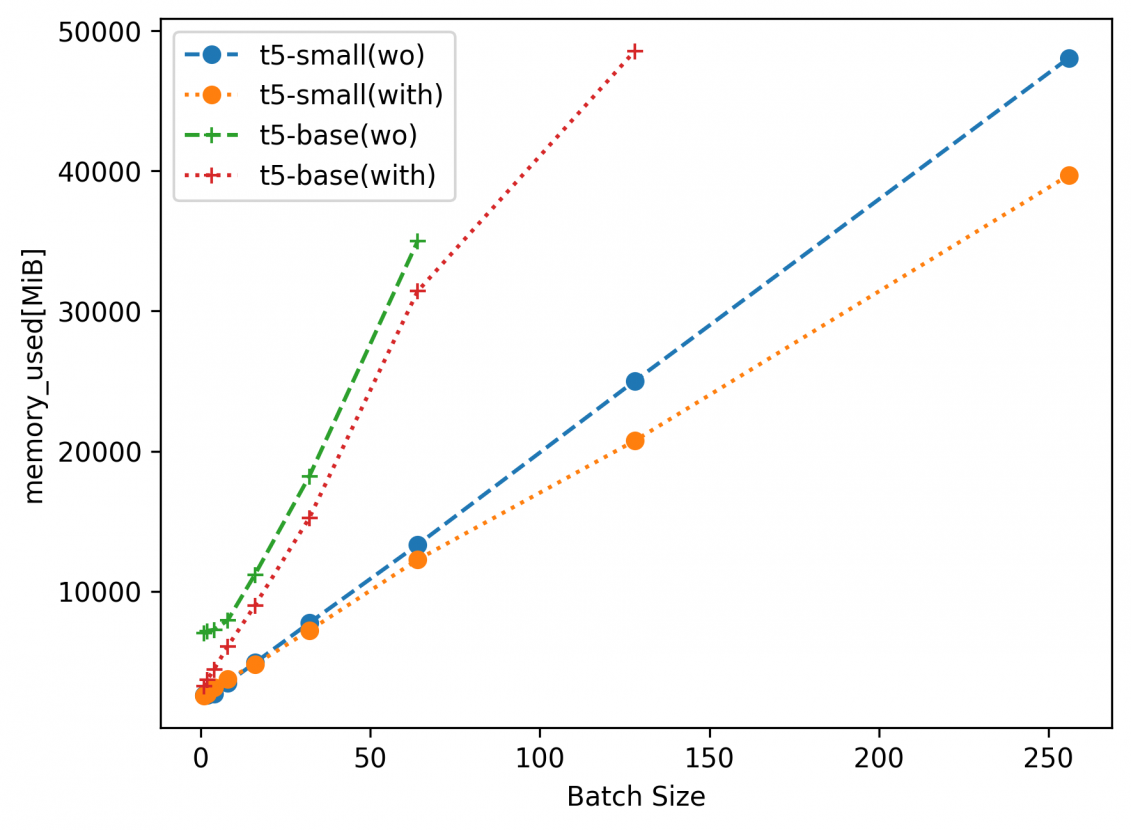
図4:GPUメモリ使用量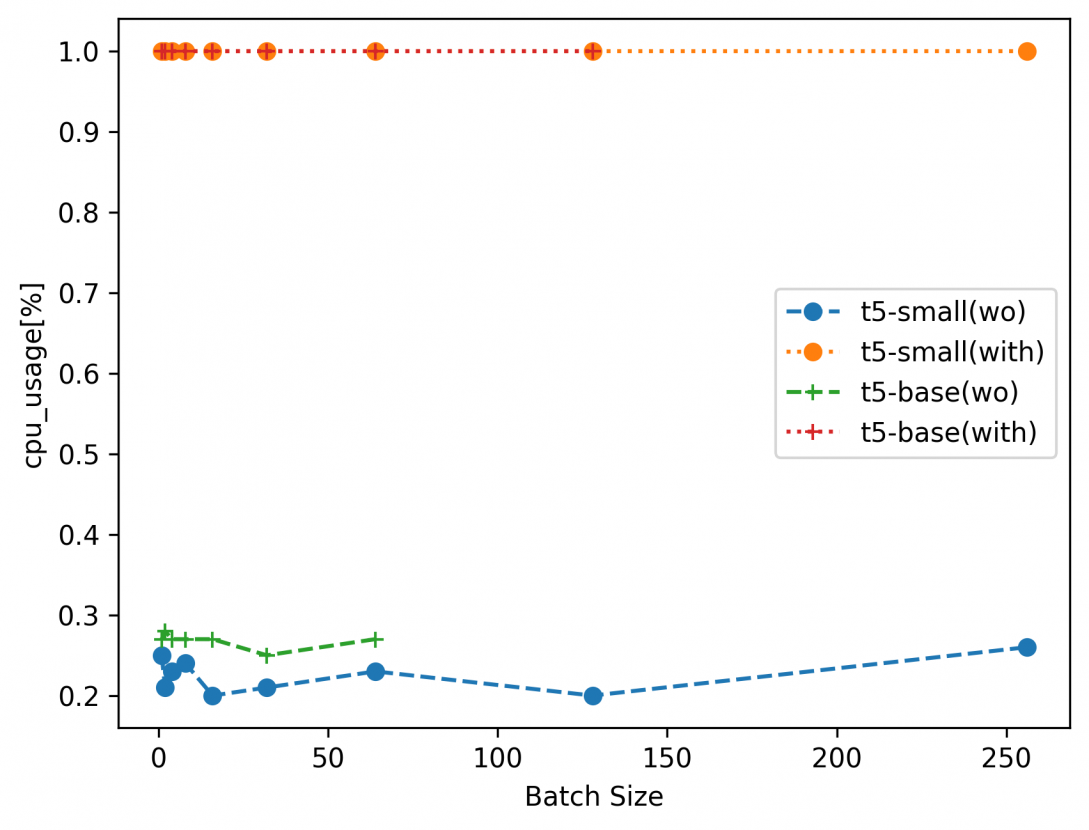
図5:CPU使用率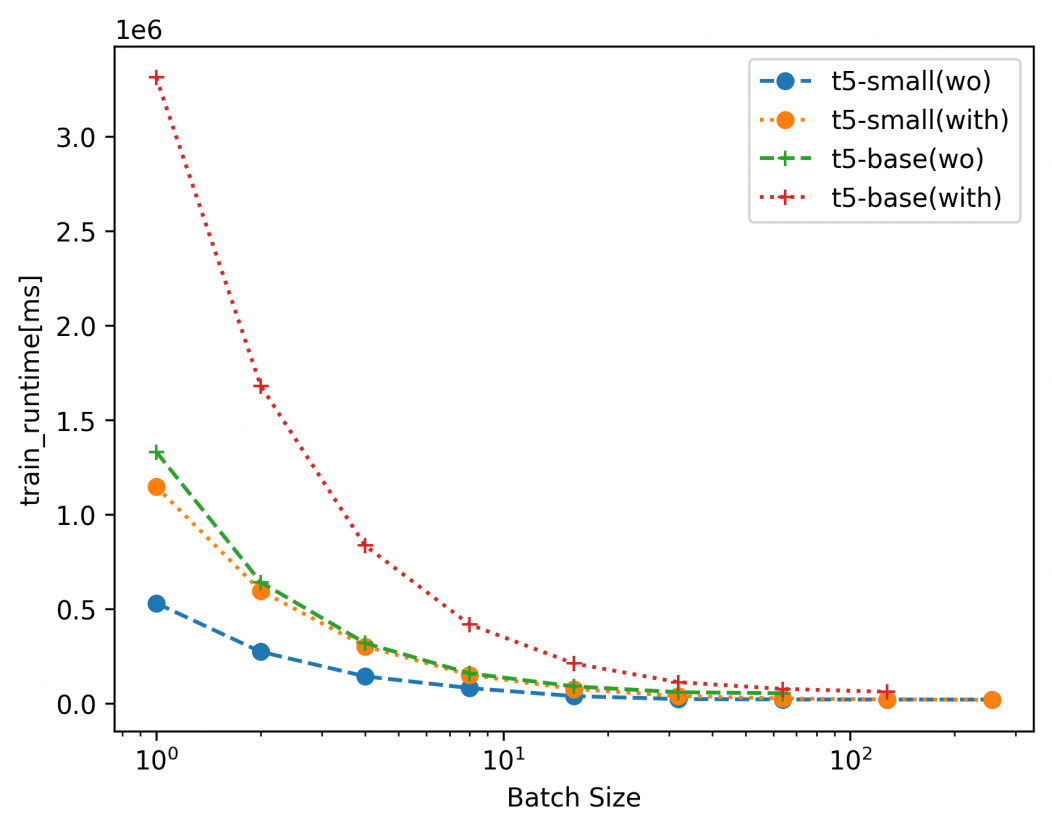
図6:訓練の所要時間
図4~6に測定結果を示します。なお、凡例はFine-tuningのベースモデルを示します。カッコ内はwoがDeepSpeed適用なし、withがDeepSpeed適用ありの結果を示します。t5-small(with)であれば、t5-smallをベースモデルに、DeepSpeedを用いてFine-tuningを行った結果を示します。プロットされていないマーカーは、GPUメモリが足りず実行できなかったパラメタになります。
まず、図4のGPUメモリ使用量を確認すると、DeepSpeedを適用することで若干ながらも抑制できていることが分かります。また、t5-baseにおいては、DeepSpeedを用いない場合バッチサイズ64までしか学習できませんが、DeepSpeedを適用することでバッチサイズ128まで学習することができていることが分かります。
図5のCPU利用率は、DeepSpeedを用いた場合常に100%に貼りついています。これはZeRO Offloadを用いることで、一部のデータがCPUにオフロードされたことによるものと考えられます。
図6の訓練の所要時間は、バッチサイズが小さい場合、DeepSpeedを適用したときのほうが遅くなる傾向にありました。いっぽうで、バッチサイズが大きくなるにつれてその差は小さくなってきています。これはCPUへのオフロードにおけるデータ転送時間がボトルネックになっていることが想像されます。
測定②:GPU2台(ZeRO Stage-2)
本測定では、複数GPUを用いて測定します。具体的には、以下のコマンドを用いて実行します(測定①からGPUの指定を省いただけになります)。なお、GPUメモリ使用量は2台のGPUメモリ使用量の合計を算出しました。なお、CPU利用率は、測定①と傾向が変わらないため割愛しました。
共通
git clone https://github.com/huggingface/transformers
cd transformersDeepSpeed適用なしの実行コマンド
python examples/pytorch/translation/run_translation.py \
--model_name_or_path ${BASE_MODEL} --per_device_train_batch_size ${BATCH_SIZE}\
--output_dir ~/output_dir --overwrite_output_dir --fp16 \
--do_train --max_train_samples 10000 --num_train_epochs 1\
--dataset_name wmt16 --dataset_config "ro-en"\
--source_lang en --target_lang roDeepSpeed(ZeRO-Offload)適用ありの実行コマンド
deepspeed examples/pytorch/translation/run_translation.py \
--deepspeed ds_config_zero2.json \
--model_name_or_path ${BASE_MODEL} --per_device_train_batch_size ${BATCH_SIZE}\
--output_dir ~/output_dir --overwrite_output_dir --fp16 \
--do_train --max_train_samples 10000 --num_train_epochs 1\
--dataset_name wmt16 --dataset_config "ro-en"\
--source_lang en --target_lang ro測定結果
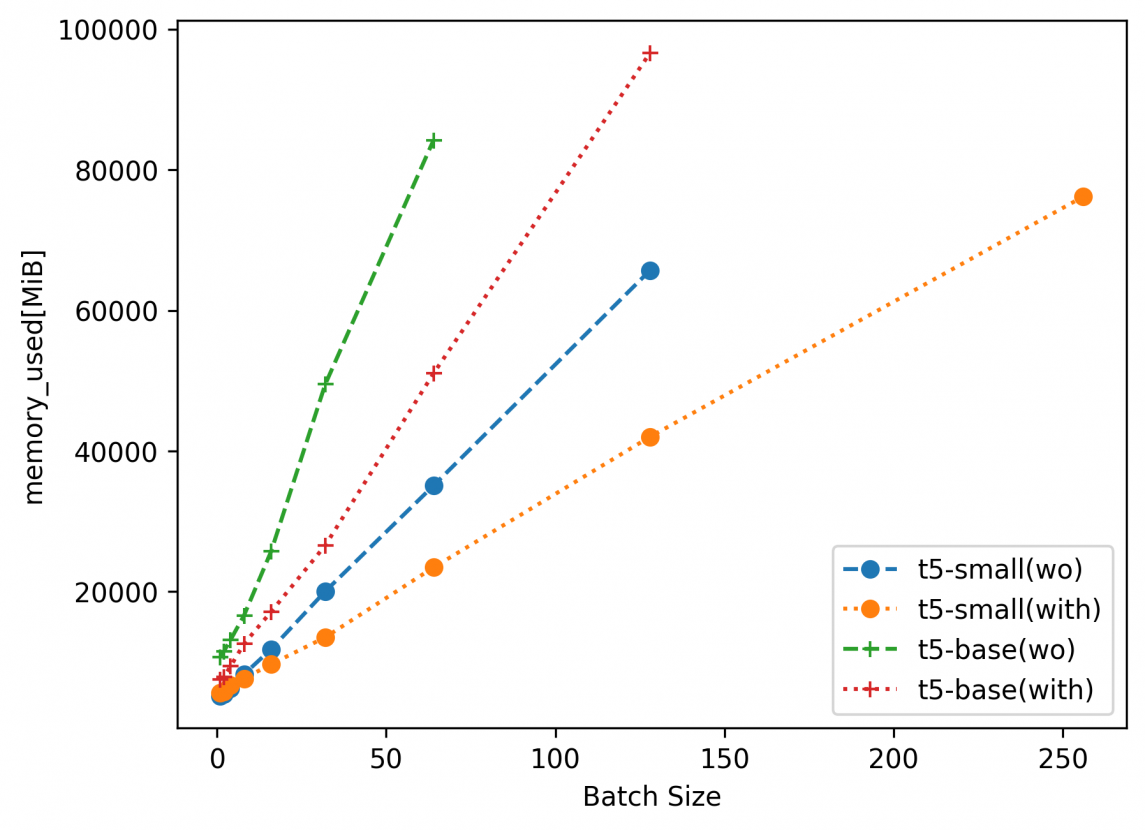
図7:GPUメモリ使用量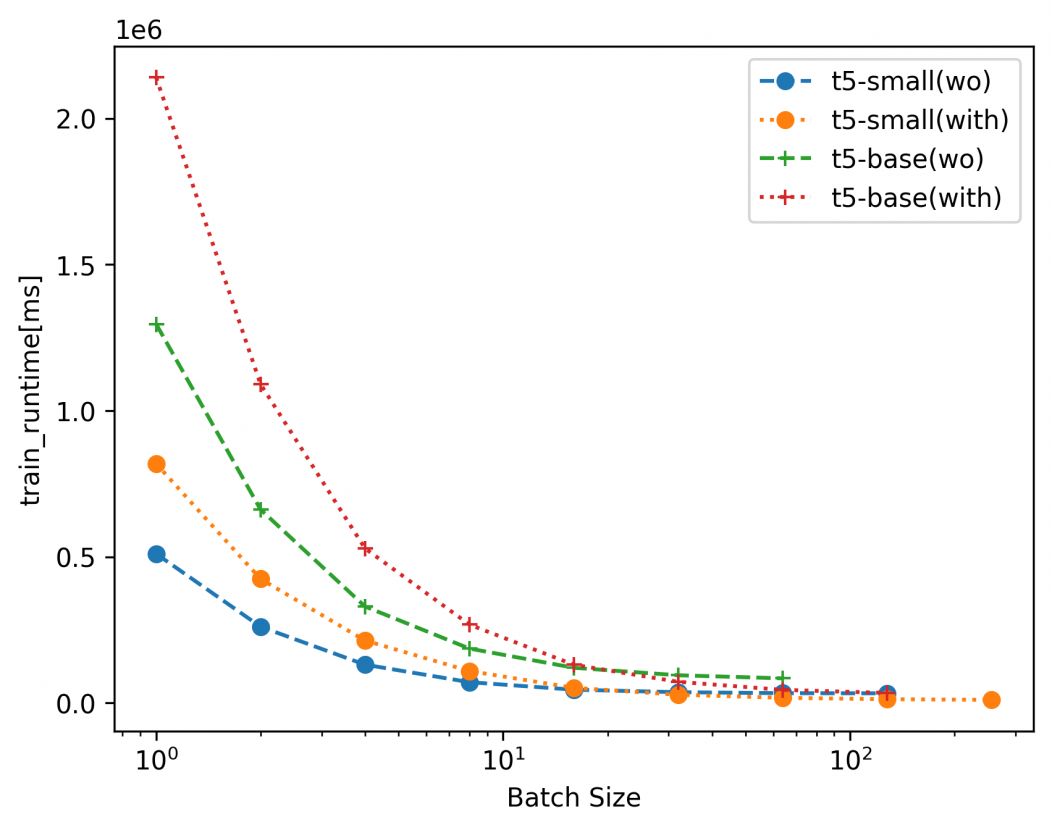
図8:訓練の所要時間
基本的には測定①と同様の傾向になりますが、一部で異なる傾向が見られています。
まずはGPUメモリ使用量に注目します。図9を用いて測定①と測定②を比較すると、分かりやすいでしょう。
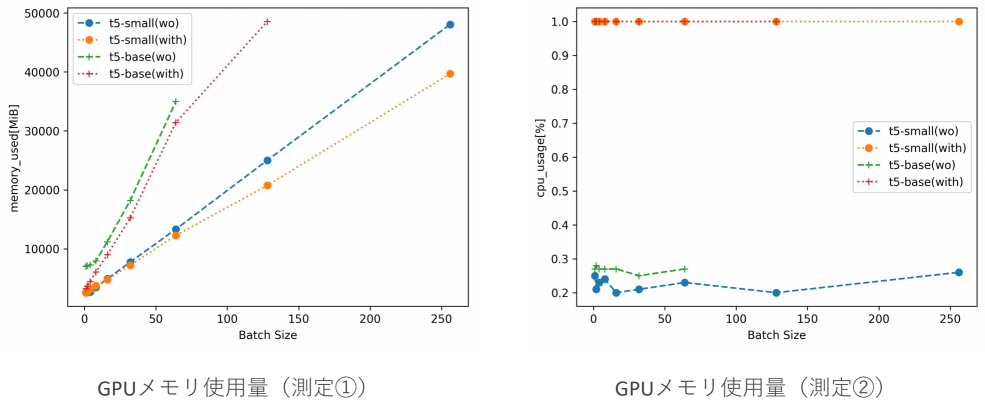
図9:測定①と測定②のGPUメモリ使用量比較
DeepSpeedを適用することでメモリ使用量を抑えることができる傾向に変わりはありませんが、測定②のほうが抑制割合がより顕著なものとなっています。これは、ZeROを用いたパラメタの分散によるメモリ効率化によるものと考えられます。すなわち、ZeROを用いない場合はモデルのパラメタをまるごとGPUメモリにのせる一方で、ZeROを用いる場合はモデルのパラメタを分割してGPUメモリにのせることができるため、1台のGPUを用いるよりもより効率的にGPUメモリを抑制できたと考えられます。
図8の訓練の所要時間についても、基本的な傾向は変わらないものの、バッチサイズが52よりも大きくなると、DeepSpeedを用いたときのほうが高速になりました。これは、バッチサイズが大きくなることによりGPUメモリへのデータ転送量が増加したことが関係していると考えられます。このような時、DeepSpeedを用いたパラメタ分散により、メモリへのデータ転送量を抑制することができ、結果としてボトルネックになりやすいデータ転送時間の抑制につながったと考えられます。
実験のまとめと感想
本実験を通し、以下のことが確認できました。
- DeepSpeedを活用することで必要なGPUメモリを抑えられること
- ケースによっては学習速度を縮められること
利用には少しノウハウが必要ですが、コツを掴めばより大規模学習にも活用できるツールであることを感じました。今回は検証できませんでしたが、より高速な記憶媒体であるMNVeにパラメタをオフロードする機能Zero-Infinityも存在します。MNVeであれば、GPUよりもより低コストで大きなメモリを確保できるため、(多少遅くなるとは思われますが)なかなか実現しづらかったサイズのLLM検証も期待できるようになります。また、今回は学習をターゲットにしましたが、推論においてもいくつかの機能が搭載されているため、こちらも検証できればと思っています。
おわりに
本記事では、Microsoftが開発した深層学習向け高速化・省メモリ化ライブラリDeepSpeedを取り上げ、具体的な特徴と導入手順、実験結果を紹介しました。実験を通し、DeepSpeedを活用することで必要なGPUメモリを抑えられること、ケースによっては学習速度を縮められることが分かりました。
AI活用においては、AIができることだけではなく、マシンスペックの制約を下げコスト抑制につなげること、高速化を通してより快適に使用できることが重要です。DeepSpeedはそのための技術のひとつとなりうるでしょう。本記事を通して、DeepSpeedに対する知見が深まれば、筆者としては喜ばしい限りです。
さいごに、ARISE analyticsではKDDIグループを支えるためのAI技術開発を行っています。今回紹介した内容や、その他記事で触れている弊社の取り組みに興味がございましたらぜひお声がけください。
▼採用ページはこちら
https://www.ariseanalytics.com/recruit/
