Marketing Solution Division所属のエンジニアの坂本です。
FaaSデプロイの悩み
早速本題ですが、AWS Lambdaのデプロイについて悩んでませんか?
そうした際に役に立つのがServerless Framework(以下、Serverless)などのFaaS用構成管理デプロイツールです。
そこで今回は社内で開発したSlackのChatBotで使用した構成を例に話していきたいと思います。
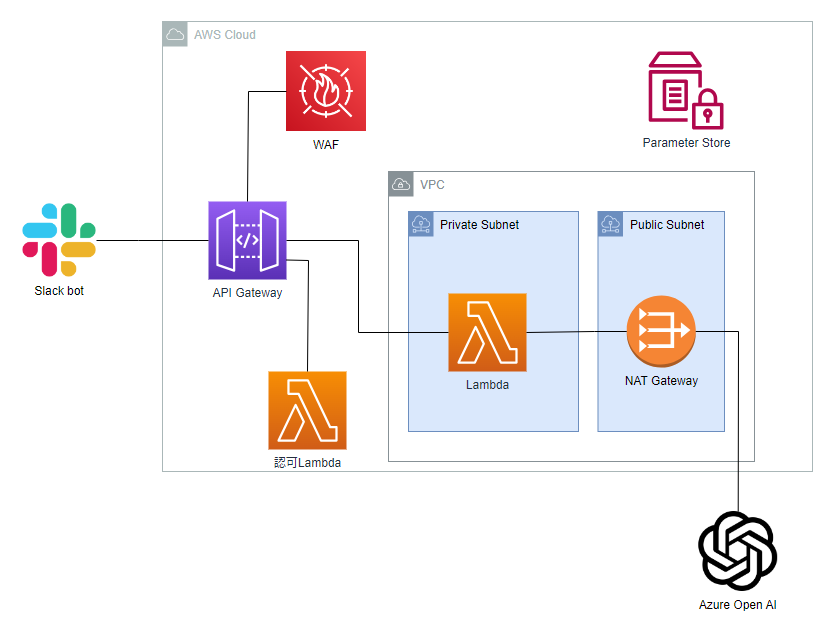
中身としてはシンプルにSlack botからのREST通信をAPI-Gatewayで受けて、WAF及び認可Lambdaを通過すれば、Lambdaで内容を処理をしてAzure上のOpen AIに投げるといった構成にしています。
インフラとアプリの責任分界点
結論
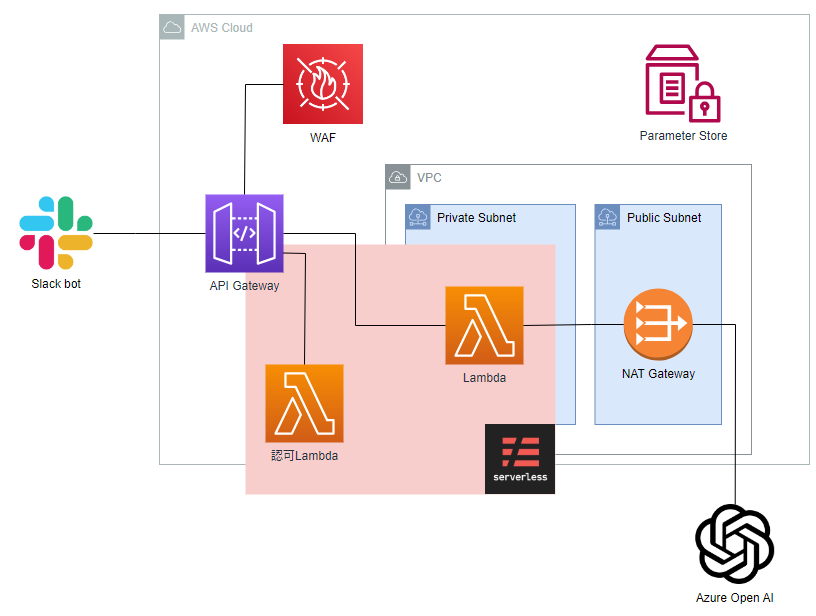
最初に結論からいうと今回のServerlessの構成としては下記の図と表のようになっています。
構成図(Severless以外は全てTerraform管理)
リソース対応表
|
リソース |
Terraform |
Serverless framework |
|---|---|---|
|
VPC(subnet, NAT含む) |
〇 |
|
|
WAF |
〇 |
|
|
Parameter store |
〇 |
△ ※read only |
|
API Gateway(REST API) |
〇 |
|
|
API Gateway(リソース) |
△ ※初回作成のみ |
〇 |
|
API Gateway(ステージ) |
△ ※初回作成のみ |
〇 |
|
Lambda |
|
〇 |
※API Gatewayのリソースとステージは作成必須のため初回のみ構築し、Terraform上では変更を検知しないようにしています。
おそらく大半の方はServerless側にAPI Gatewayを寄せているかと思いますが、何故このような構成にしたかを説明させていただければと思います。
理由
今回寄せなかった理由は一重に、インフラの設計はインフラで一旦管理したかったというのがあります。
そうなるとインフラリソースであるWAFなどをSeverless側に寄せると今後の拡張の際にSeverlessとTerraformどちらに寄せるかを毎回考えなくてはいけなくなりますし、明確な定義をしないとその時担当した人によって設計がズレてしまう。というのはよくある話かと思います。
そうなった場合の考え方としてたどり着いたのが、アプリ部分以外は完全にTerraformに寄せる今回の作りでした。悩ましかったのはAPI Gatewayの部分ですが、接続先のリソースがないとデプロイできないこと、レスポンスなどアプリ側で決めるべきことが設定内に組み込まれていることからSeverless側に寄せることにしました。
これであればAWSの知識がないアプリエンジニアもSeverlessの設計に取られる時間が最低限で済みますし、アプリのリクエスト・レスポンスにまつわる設定を全てSeverless側にまとめることができました。
Severless側全体をインフラエンジニアはアプリから解放されるので今後アサインされるメンバー選定の際にインフラ、アプリに跨った技術スタックを持つ人物である必要はなくなります。また、アプリとインフラ両方できる人でも新しいリソース(例えばDynamoDBなど)をSeverlessで管理するかTerraformで管理するか悩まず、Severlessは最低限という設計思想からTerraformに寄せることができます。
それでは実際のseverlessコードを見てみます。
serverless.yml(一部今回の件と関係ない部分はカットしています。
service: arise-slack-llm
frameworkVersion: '3'
provider:
name: aws
stage: ${opt:stage} # 各環境ごとの差分吸収のために外部変数をセット
region: ap-northeast-1
runtime: python3.9
apiGateway:
restApiId: ${ssm:/genai/apigw/chatbot/id}
restApiRootResourceId: ${ssm:/genai/apigw/chatbot/root_resource_id}
tags:
CreatedBy: Serverless
System: genai
stackTags:
CreatedBy: Serverless
System: genai
stackName: genai-${self:provider.stage}-clf-stack-01
package:
individually: true
exclude:
- ./**
functions:
ariseSlackLlmLambda:
name: genai-${self:provider.stage}-lambda-chatbot-01
description: Chatbot Lambda
role: ${ssm:/genai/iam/chatbot_lambda_invoke/id}
handler: src/slack_llm_bot/app.handler
provisionedConcurrency: 1
memorySize: 512
timeout: 29
package:
include:
- ./src/**
exclude:
- ./src/authorizer/auth.py
environment:
PYTHONPATH: /var/task/src
events:
- http:
path: /{proxy+}
method: ANY
authorizer:
name: authLambda
type: request
identitySource: method.request.header.X-Slack-Signature
vpc:
securityGroupIds:
- ${ssm:/genai/sg/chatbot/root_resource_id}
subnetIds: ${ssm:/genai/vpc/chatbot/id}
authLambda:
name: genai-${self:provider.stage}-lambda-authorizer-01
description: Authorizer Lambda
role: ${ssm:/genai/iam/auth_lambda_invoke/id}
handler: src/authorizer/auth.handler
memorySize: 256
timeout: 6
package:
include:
- ./src/authorizer/auth.py途中各所に${ssm:/xxxx}という変数名が入っていますが、こちらはTerraformがSeverless側で必要なリソースを作成した際にIDをParameter storeに格納し、そちらを呼び出しています。
Terraform側のコードは下記のようになります。
main.tf(こちらも説明に不要なリソースは削除しています)
# ------
# api-gateway
# ------
resource "aws_api_gateway_rest_api" "apigw_chatbot_01" {
name = "${var.system}-${var.env}-apigw-01"
description = "GenAI chatbot REST API Gateway"
endpoint_configuration {
types = ["REGIONAL"]
}
}
# ------
# ssm-parameter store(API-GW)
# ------
resource "aws_ssm_parameter" "ssm_parameter_apigw_id_01" {
name = "/genai/apigw/chatbot/id"
description = "API Gateway ID of chatbot"
type = "String"
value = aws_api_gateway_rest_api.apigw_chatbot_01.id
}これにより、インフラで作成したリソースidをパラメータストアに格納しており、Severless側が取得することによって依存関係もTerraform→Severlessとなっているため、再帰的な依存や相互依存を防ぐことができ非常にシンプルな管理を実現しています。
メリット
理由の項目にも記載しましたが、上記の構成を実現したことによるメリットとしては
- IaCとアプリケーション部分が分離させているため、責任分界点がわかりやすい
∟Lambdaを含めたアプリケーションのロジック、リクエスト、レスポンスにかかわる部分はSeverless側の変更で完結
∟逆にWAFやVPCなどといったインフラリソースはTerraform側のみの設定、デプロイが完結 - 新規のAWSリソースを追加する際にも上記を念頭におけばよいので、人による設計にバラつきがない
といった点が挙げられます。
まとめ
クラウド化が進み、インフラとアプリとの境目が難しくなってきています。
