はじめに
ARISE analytics の近藤です。本記事では、次世代の意思決定技術として注目されている反実仮想機械学習(Counterfactual Machine Learning:CFML)を紹介します。
本記事は、CFMLを日本語で体系的に整理し、初学者の理解を手助けすることをねらいとして執筆しました。本記事の理解促進につながるように、ベースとなった勉強会資料を記載します。こちらも併せて閲覧いただくことで理解の助けになれば幸いです。
目次
・ はじめに
・ Counterfactual Machine Learning(CFML)
・ Off-Policy Evaluation(OPE)
・ CFMLを支える技術(オープンデータとツール)
・ おわりに
Counterfactual Machine Learning(CFML)
CFMLをめぐるトレンドとビジネス
CFMLは産業界・学術界でも注目を浴びており、非常にホットな技術です。
産業界では、レコメンド領域で活用されています。たとえば、Netflixのような動画視聴サービスやZOZO TOWNのようなECサービス上で動作するレコメンドアルゴリズムの評価にCFMLが導入されています。
学術界では、推薦システムのトップカンファレンスであるRecSysでもCFMLを扱った論文”Pessimistic Reward Models for Off-Policy Learning in Recommendation”がBest Paperに選出されました。
それだけではなく、説明可能なAI(XAI:eXplainalbe AI)にも導入が進んでおり、説明性の向上を目的としてCFMLを統合したCounterfactual XAIが提案されています。
ARISE analyticsでは、「au PAY」や「auスマートパス」を提供しているKDDIのライフデザイン事業のマーケティング支援を行っています。マーケティングにおいては、顧客体験向上を目的としたプロモーションやキャンペーン(施策)が重要になります。
そこで、ARISE analyticsではより効果的な施策提案を目的としたCFMLのビジネス適用を検討しています。
マーケティングにおいて課題となるのが施策実行コストです。一般的に、プロモーションやキャンペーンはある程度の期間にわたって行われ、費用もかかります。日経広告研究所の報告では、国内の有力企業3258社の広告宣伝費総額は6兆1275億円と報告されています。企業によって差がありますが、KDDIのようなBtoC企業では特に広告宣伝費が大きくなる傾向にあります。
そのため、広告宣伝費の有効活用が求められています。費用対効果の大きい施策に絞り込むことで広告宣伝費を1%でも削減することができれば、金額的に大きなインパクトが期待できるでしょう。
この背景を踏まえ、施策実行前の施策効果測定による費用対効果の算出が求められています。これを実現するための技術が、反実仮想機械学習(Counterfactual Machine Learning:CFML)です。
Counterfactualとは
CFMLを説明するにあたり、まずはCounterfactual(反事実)がどういったものかを説明します。
Counterfactualは観測され得たけど、実際には観測されなかったデータのことを指します。別の言葉では、Potential Outcome(ポテンシャルアウトカム)とも呼ばれます。
例示は理解の試金石という言葉があるように、具体的な事例は理解促進につながります。ここでも事例を挙げてCounterfactualを考えてみましょう。
ケース
・何らかの病気症状を持つ個体(ここでは個体Aとする)がいる。
・個体に対し、特定の薬を投薬するか否かを選択できる。
個体Aは「投薬あり」を選択することにしました。この結果、個体Aの病気症状は改善されました。
さて、ここで懐疑的な見方をすると、以下のような疑問が生じます。
今回投薬した薬は、個体Aが罹患していた症状に対してほんとうに効果があったのか?
「投薬なし」を選択していても、今回の症状は治癒していた可能性があります。
薬が本当に効果があったのかを確認するためには、「投薬なし」の結果も観測する必要があります。
しかし、個体Aはすでに「投薬あり」を選択していたため、時間を巻き戻して「投薬なし」の結果を取得することはできません。このように、実際に取った行動とは異なる選択肢から得られる結果(観測されなかった結果)を、Counterfactualと呼びます。
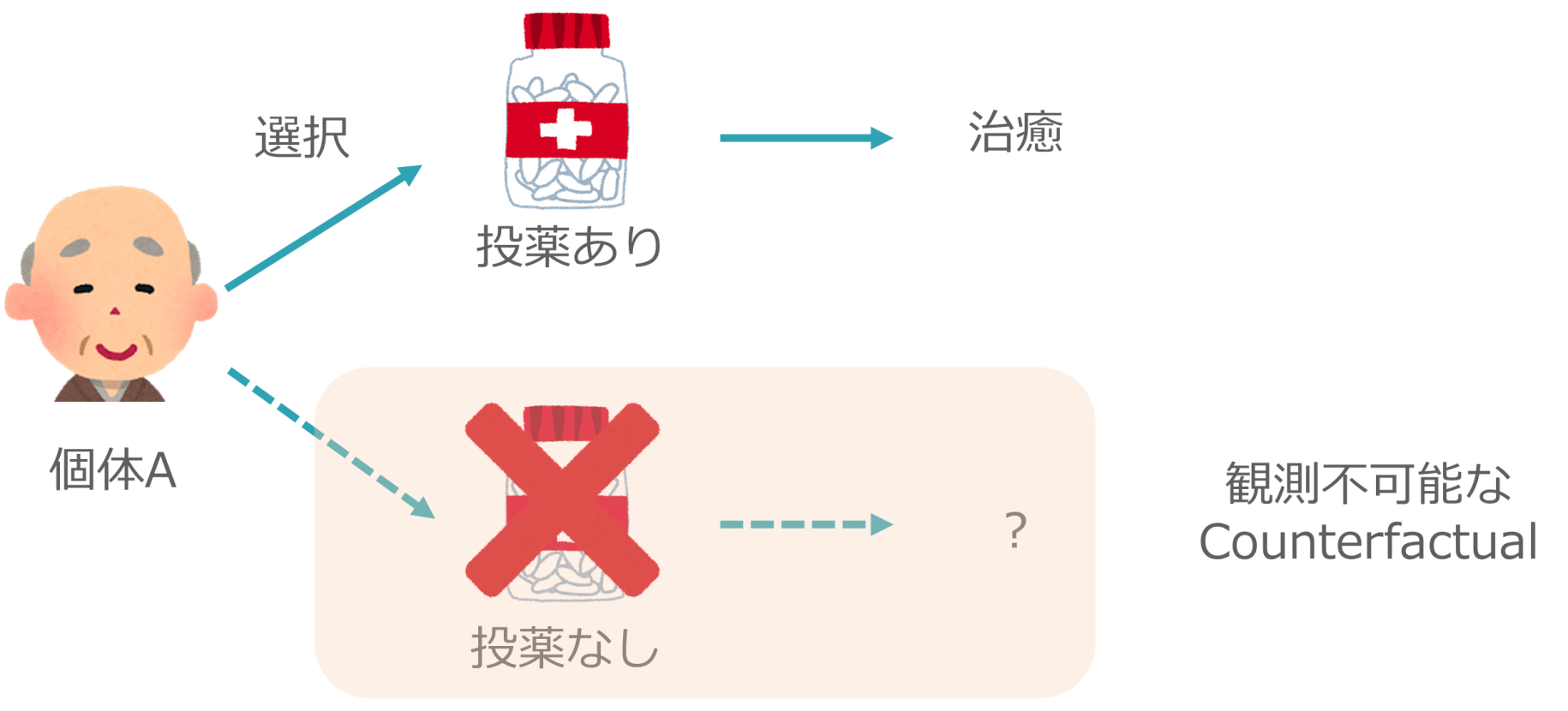
Counterfactualと統計的因果推論
統計的因果推論はCounterfactualを疑似的に観測して評価するための方法のひとつです。以下の資料が詳しいため、本記事では簡単な説明に留めます。
Counterfactualを観測するためには同一の個体を複数用意し、それぞれ別の行動を取らせる必要があります。しかし、現実的にはできません。
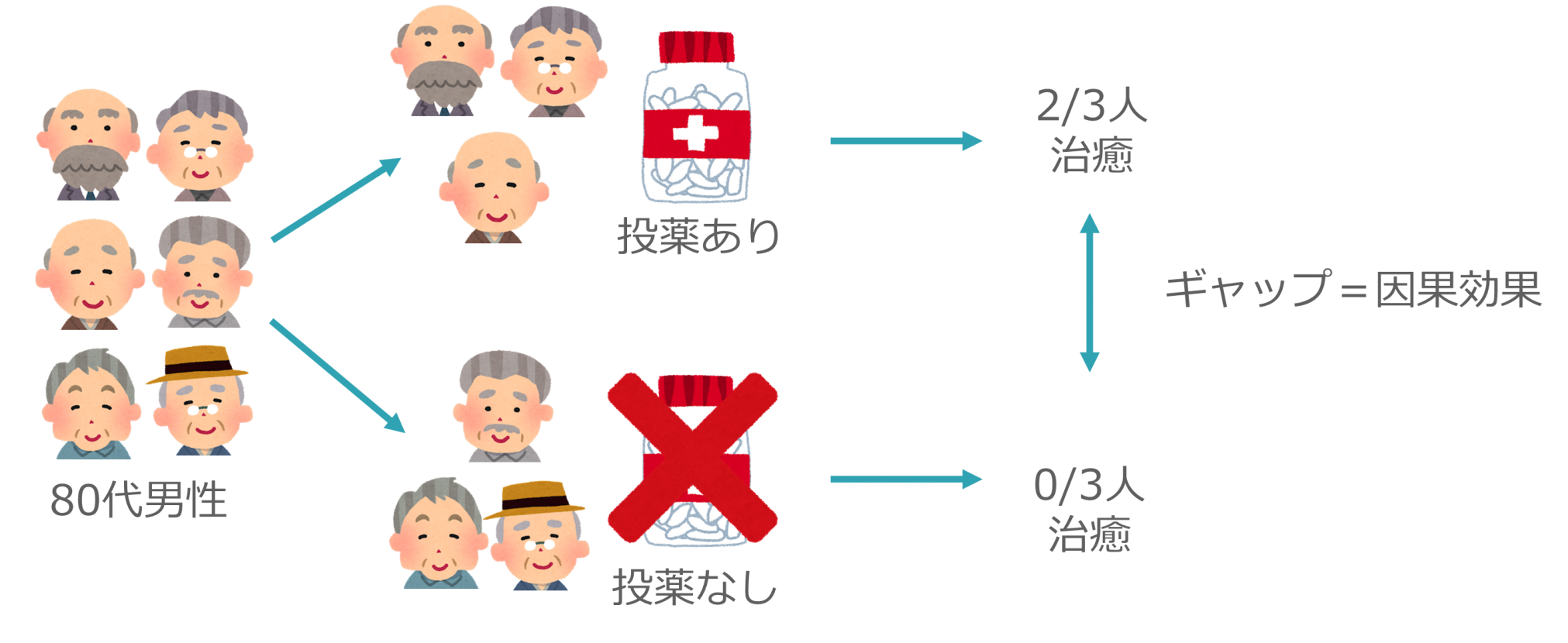
そこで、ある程度似た特徴を持つユーザ集団(例:80代・男性)を用意します。このとき、評価内容には影響がなさそうな細かい条件の違い(例:眼鏡の有無、髪の長さ、など)には目をつむります。このユーザ集団を無作為に分割(サンプリング)して2つの集団に分けます。
このようにして作成された2つのユーザ集団は、どちらも似た要素を持っているため統計的には同じものとみなすことができます。したがって、ユーザ集団それぞれに異なる選択をとらせることで、選択の効果(=因果効果)を測定できます(いわゆるA/Bテストとも呼ばれます)。
Counterfactual Machine Learning(CFML)とは
統計的因果推論がうまく適用できないケースも存在します。
たとえば、ユーザ属性に基づいたレコメンドやクーポン配布です。レコメンドを例にして説明します。
ECショッピングのレコメンドでは、ユーザの年齢や性別、商品の閲覧履歴といった特徴に基づいて商品のレコメンドを行うことがほとんどです。すなわち、似た特徴を持つユーザに対しては同じようなレコメンド結果しか返ってきません。
具体的には、以下の表のようなケースです。ユーザAとユーザDは似た特徴を持っていたため、レコメンドアルゴリズムはアイテム1を推薦しています。
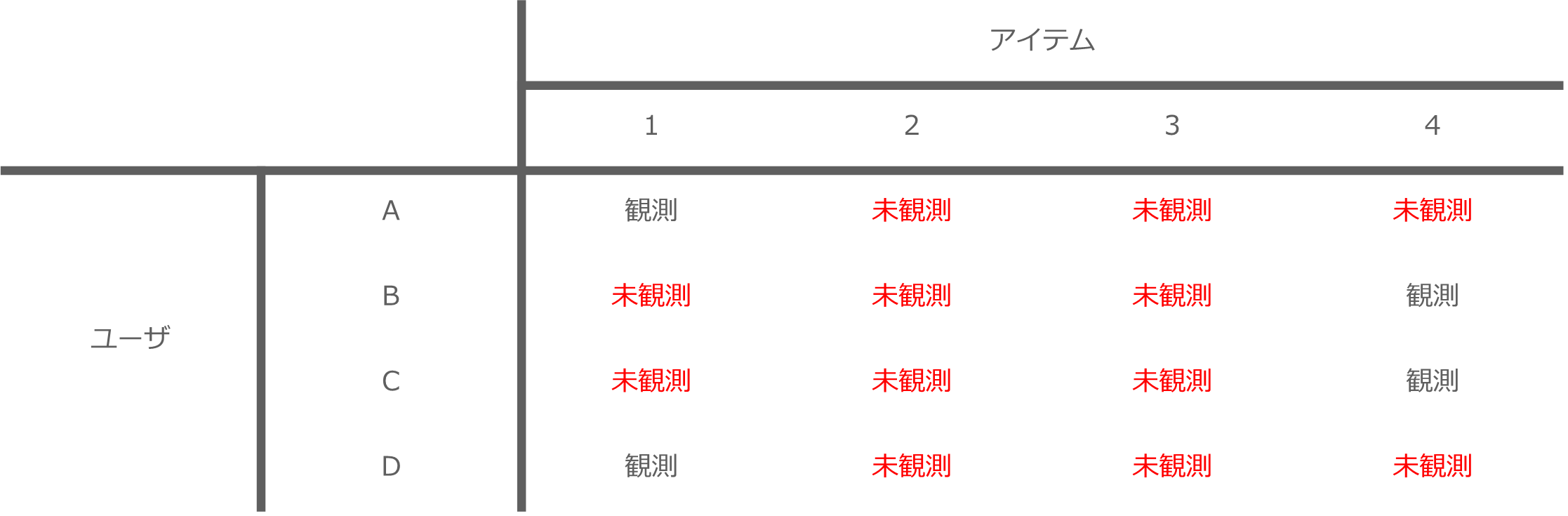
統計的因果推論を用いて因果効果を測定するためには、似た特徴を持つユーザ集団を無作為分割して異なる選択肢を取らせ比較する必要があります。しかし、レコメンドでは似た特徴を持つユーザに与えられる選択肢はすべて同じです。したがって、異なる選択肢を取らせることができません。
CFMLでは観測範囲が限られたログデータから未観測範囲(Counterfactual World)を疑似的に観測することを目指します。これにより、レコメンドアルゴリズムや施策の本来の効果(因果効果)を測定できるようにします。そして、新しいアルゴリズムや施策を導入し、全体最適化を狙います。これがCFMLの目的です。

Off-Policy Evaluation(OPE)
この章以降は数式や記号が頻出するため、ここで先に整理します。公開サイトの仕様上、下付き文字などの添え字・数式表記が難しいため多少見づらいところがあるかと思いますが、ご容赦頂ければ幸いです。

OPEの考え方
CFMLの目的は、未観測領域を含めた全体最適化です。
そのため、レコメンドアルゴリズムや施策(=Policy)の本来の効果を測定するだけでは不十分です。全体がより良くなるようにPolicyを改良して、初めて目的が達成されます。
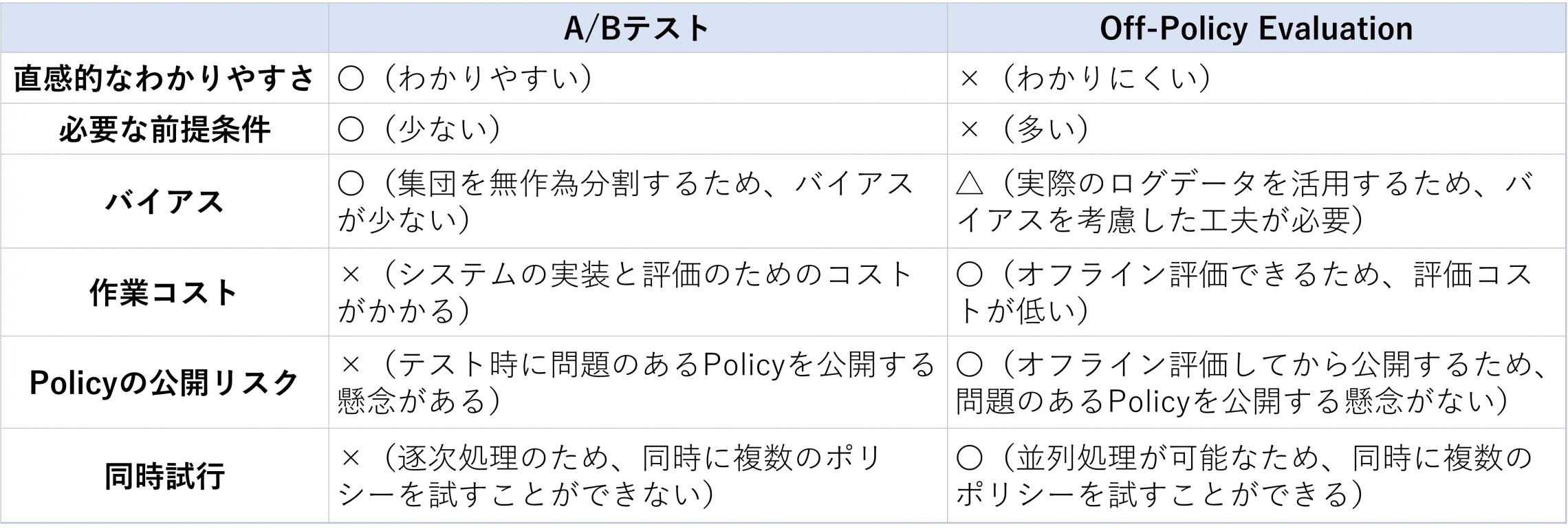
ただし、事前に十分なテストをしないままいきなり本番環境にPolicyを導入するのは非常にリスクのある行為です。そのため、事前にA/Bテストなどの試験を用いて評価することが求められます。ここでよい結果が得られたら、本番環境に導入します。しかし、このような試験には時間も手間もかかります。
そこで、試験を仮想的に行うことでコストを抑えるOff-Policy Evaluation(OPE:オフ方策評価)が提案されました。OPEでは過去のPolicyの運用で蓄積されたログデータを活用し、新しいPolicyの評価を行います。したがって、(筆者の知る限りでは)最初に運用したPolicyにはOPEの適用ができない点には注意が必要です。
OPEでは、目的とする試験に合わせて評価方法を設計します。設計には様々な考え方がありますが、今回はA/Bテストを例に挙げ、同等の評価ができることを考えます(今回はA/Bテストを例に挙げましたが、ほかの方法を近似してもかまいません)。
まずは、A/Bテストで得られる評価結果を定義しましょう。
以下の図のように、リクエスト i があったとき、ユーザ情報 x に基づき特定のAction a を返すPolicy π を考えます。このとき、Action a に対するユーザの行動はReward r として定義できます。

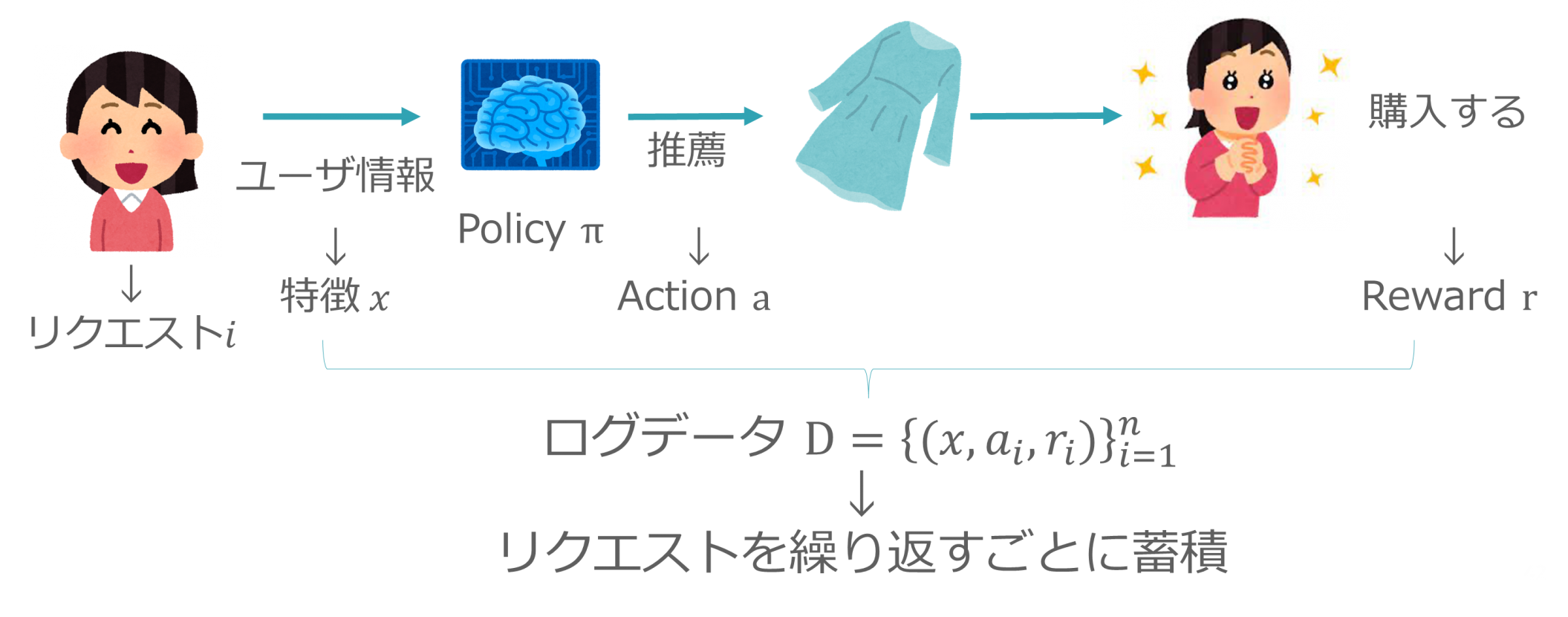
リクエストをn回繰り返したときのふるまいをログデータD = { (x, a_i, r_i) }^n_i=1 として定義します。1つのレコードごとに、ユーザ情報 x 、Action a 、Reward r が記録されています。
Policy π_e に対する A/B テストを実行したとみなし、その時のログデータ D_e から Policy π_e の価値 V^(^)_(A/B) を計算してみましょう。以下の式で算出できます。この式では、Reward r の総和平均を取っています。別の言葉で言い換えると、ユーザに期待する行動をしてもらえた割合になります。
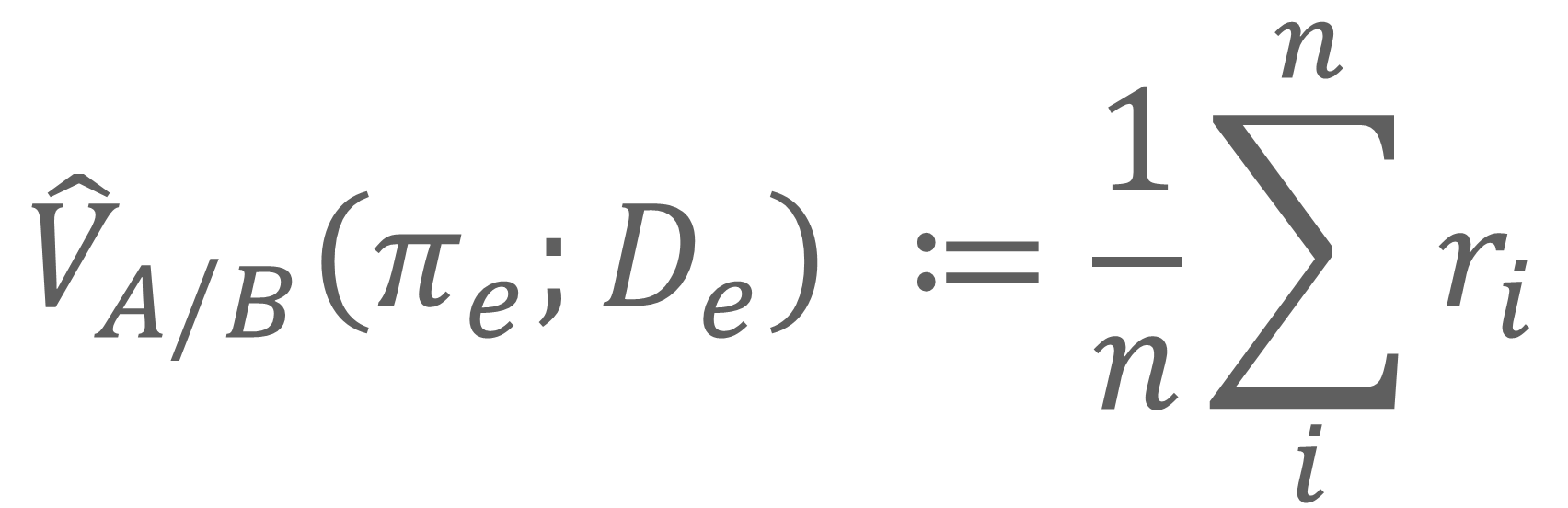
つぎに、OPEでA/Bテストを近似することを考えます。
古いPolicy π_0 がすでにシステム上で動いており、ログデータ D_0 が得られるケースを考えます。ログデータ D_0 を活用することで、新しい Policy π_e の評価ができればよさそうです。
そこで、ログデータ D_0 と新しい Policy π_e を入力して価値V^(^)を算出することを考えます。ここで目的とするのは、本来の価値を算出することですから、以下のような近似を目指します。

近似の評価は、以下のように平均二乗誤差(MSE:Mean Square Error)で算出します。
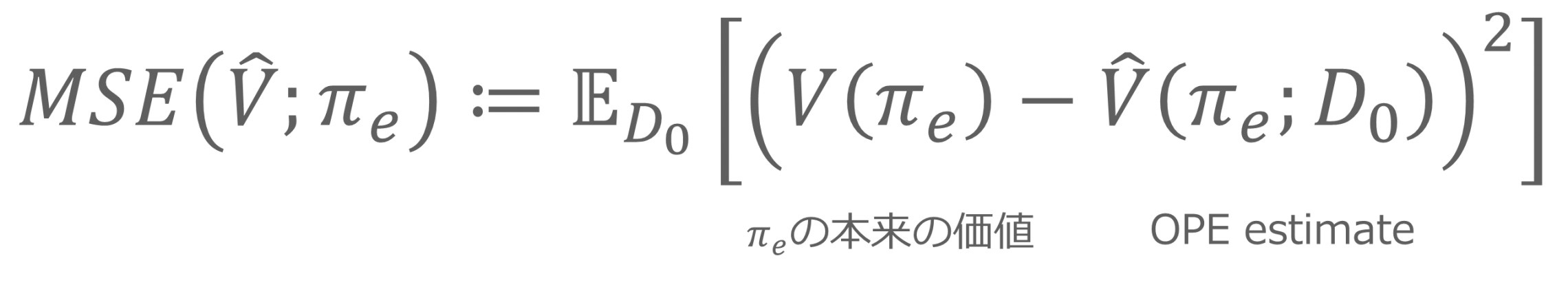
OPEを用いて新しいPolicy π_eの価値を算出するための関数 V^(^)(π_e; D_0) をOPE Estiamteと呼びます。OPE Estiamte は、MSEが可能な限り小さくなるように設計することがポイントです。
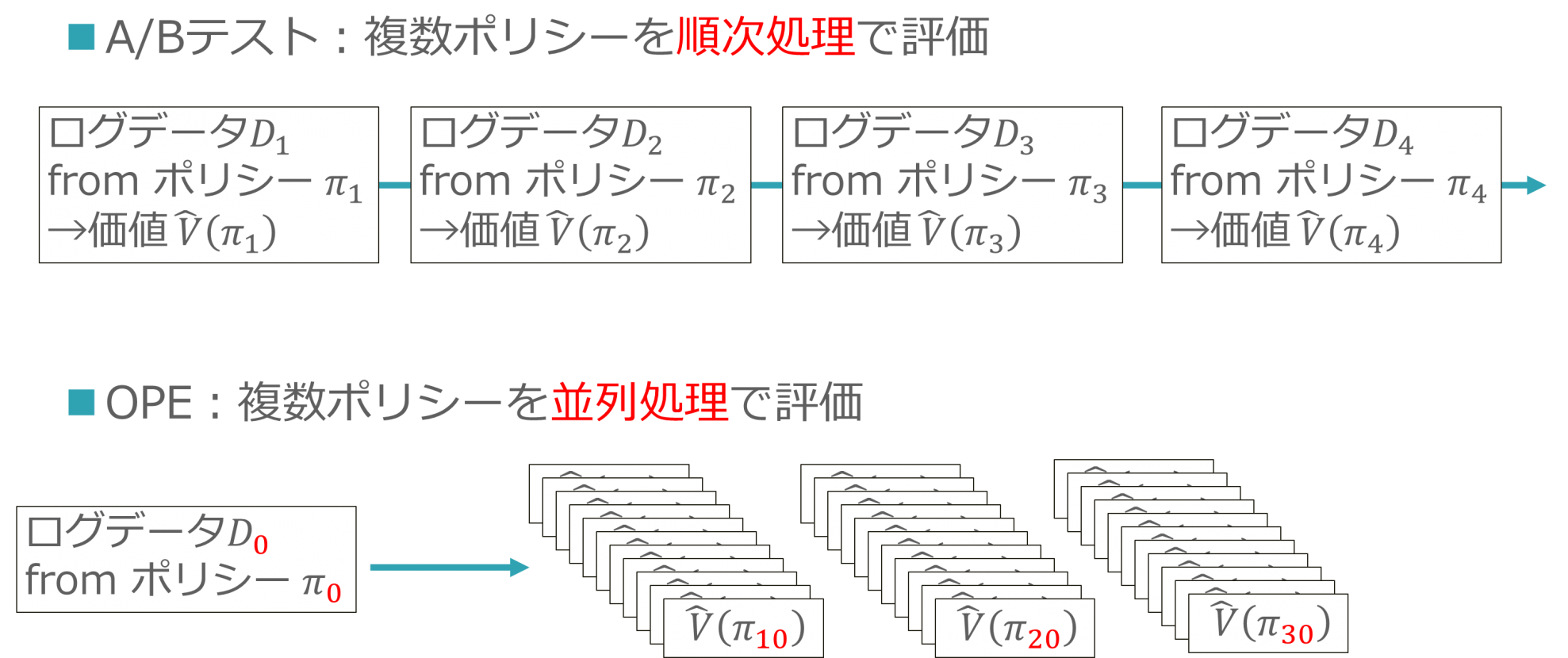
OPEの利点として、ここまでで説明したオフライン評価が可能な点のほか、並列処理が可能な点が挙げられます。OPEでは、ログデータ D_0 さえあればどんどんPolicy π_n を入れ替えて評価することが可能です。すなわち、以下のような並列評価が可能です。

OPEの既存手法
OPEに求められる ①必要な前提条件、 ②OPE Estiamteの適切な設計、を満たすための代表的な手法を紹介します。本記事で紹介する手法は、RecSysのチュートリアルで用いられているModel-Base OPE、Model-Free OPE、Hybrid OPEと同様に分類しています。
詳細は後ほど記載しますが、以下に簡単な概要を記載します。
・Model-Base OPE:報酬推定モデルを用いて未観測領域の疑似的な観測(推定)を行い、Policyを評価
・Model-Free OPE:観測領域のバイアスを解消することで、Policyを評価
・Hybrid OPE:未観測領域の疑似的な観測および観測領域のバイアス解消を同時に行い、Policyを評価
なお、前提条件としてPolicyはThompson Samplingのような条件付き確率(傾向スコア)を出力するものとします。
Model-base OPE
もともと考えていたことは、Counterfactualな領域(未観測領域)も含めて評価することで、Policy の本来の価値を算出することでした。
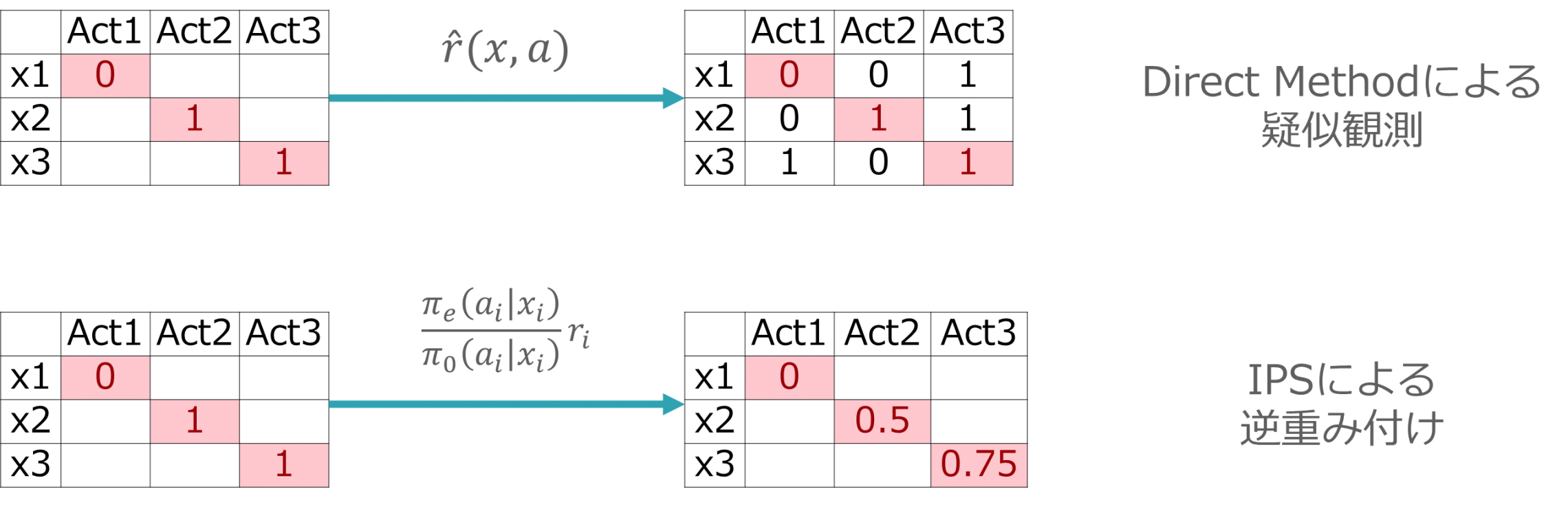
Model-base OPEの代表的な手法であるDirect Methodは、ユーザ情報 x とAction a を入力することでReward r を出力する報酬推定モデル r^(^)(x,a) を学習します(学習自体は単純な回帰モデルでかまいません)。報酬推定モデル r^(^)(x,a) に、未知の (x,a) の組み合わせを入力することで、疑似的にCounterfactualな領域を推定しよう、というものです。レコメンドを例にして言い換えると、人間の判断を模したモデルをつくり、かわりにフィードバックしてもらおう、というアイデアになります。
未観測(Counterfactual)領域を含む以下のようなログデータを考えます。
(x,a)の組み合わせのうち、未観測である組み合わせを選択し、報酬推定モデル r^(^)(x,a) に入力します。この結果得られたReward r を未観測領域の値に格納します。これにより、疑似的に未観測領域の推定が可能となります。

報酬推定モデル r^(^)(x,a) が人間の判断に近いほど高精度であることが前提となりますが、この前提を満たしていればじゅうぶんA/Bテストを近似化できるでしょう。
すべての未観測領域の推定が完了し、最終的に以下のような結果が得られたとします。

これをもとに、Policy π_eの価値を算出します。Direct Methodが算出する価値は以下の式で計算できます。

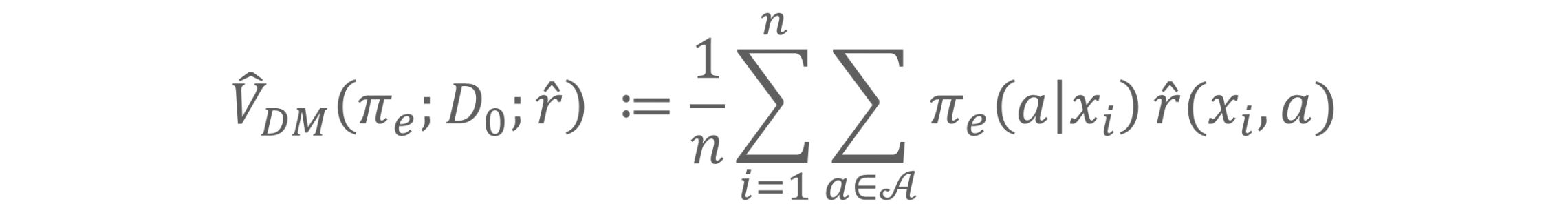
Model-Free OPE
Model-base OPEで紹介したDirect Methodでは、未観測領域の推定に用いる報酬推定モデルの学習にログデータを用いています。しかし、このログデータは前述したようにバイアスがあります。したがって、報酬推定モデルにも何らかのバイアスが生じていることが危惧されます。この場合、報酬推定モデルの出力分布は真の分布と食い違ってしまいます。
そこで、Model-Free OPEでは報酬推定モデルを使わず、観測されたデータ(ログデータ)だけを用いたPolicy評価を考えます。ただし、観測されたデータはバイアスが残っているため、これを解消できるような調整を行います。この代表的な手法が、Inverse Propensity Score (IPS) Estimatorです。
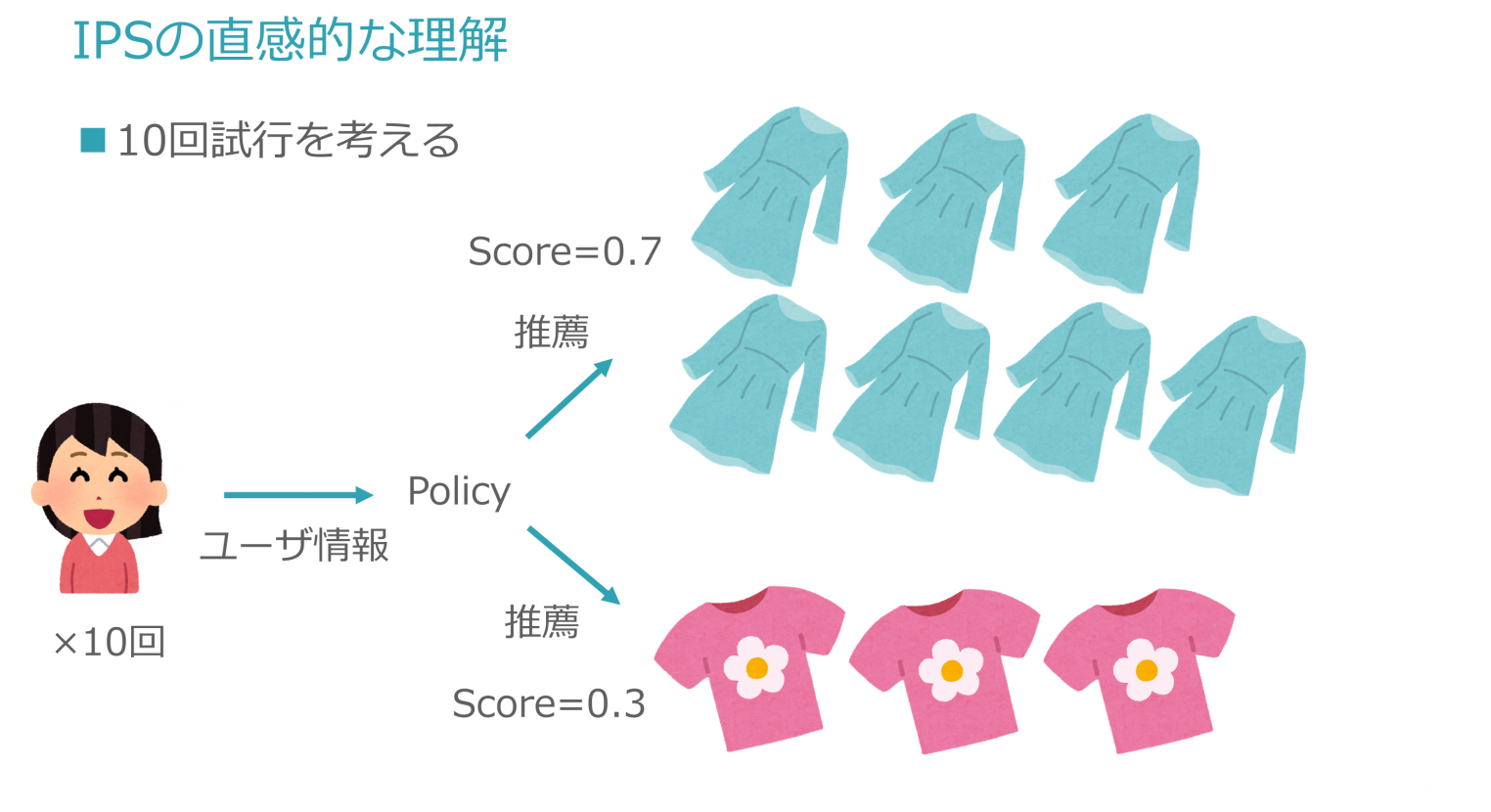
IPS Estimatorでは、Policy πから得られる傾向スコア(Propensity Score)を用います。IPS Estimatorの名の通り、傾向スコア(Propensity Score)の逆数を取り(Inverse)、重み付けに用いる手法です。たとえば、Propensity Score=0.7 であればIPS = 1/0.7 として重みに用います。
ここでいう重み付けの対象は、新しいPolicy π_e が出力する傾向スコア π_e(a|x) になります。この傾向スコアを、古いPolicy π_0 が出力する傾向スコア π_0(a|x) で割ります。これにより、全体のバイアスが解消できます。
直感的にはなかなかイメージしづらいですが、傾向スコア(≒Actionが推薦される確率)で割ることは全体の比率を均等にする効果があります。以下に例を示します。

IPS Estimator (V^(^)_IPS)の具体的な式を以下に示します。各試行ごとにPolicy π_e が出力する傾向スコアπ_e(a|x)をπ_0(a|x)で割り、Reward r に掛けたうえで総和平均をとっています。ここで計算に用いるのは、Reward r が観測された領域だけ(未観測領域の傾向スコアは用いない)である点にご注意ください。

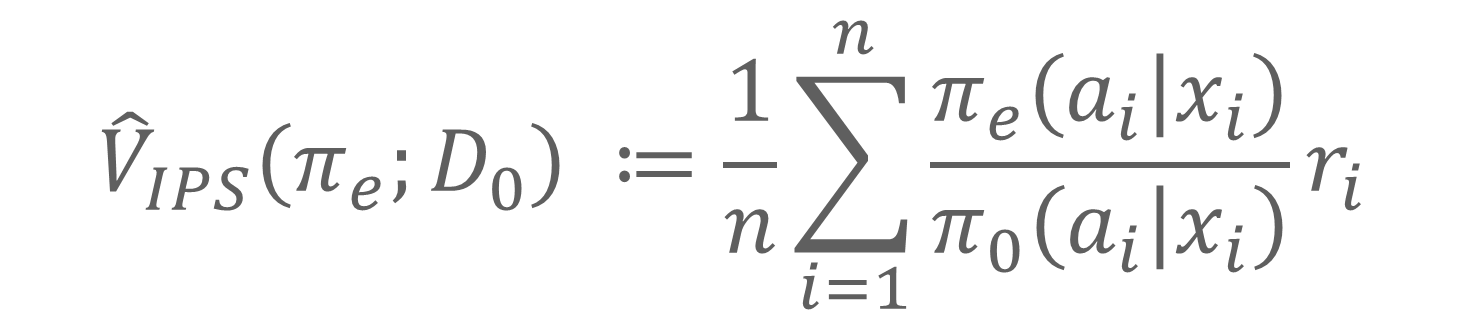

上段は結果が芳しくないPolicy π_ea を評価したときの結果を、下段は改善のため更新したPolicy π_eb を評価したときの結果を表しています。観測されたrewardはログデータ D_0 から取得しています。
まず、上段を確認してみましょう。新しいPolicy π_ea が出力する傾向スコア π_ea(a|x) は、以下のようになっています。xnとanはそれぞれユーザ情報 x とAction a を表しています。
・x1-a1(Reward r = 0):0.6
・x2-a2(Reward r = 1):0.2
・x3-a3(Reward r = 1):0.6
x1-a1 の組み合わせにおける観測されたReward r は0です。言い換えると、ユーザ情報 x1 の時にPolicy π_ea はa1 に対し相対的に高い傾向スコアを出力しています。結果として、Actionとして a1 の実行を決断したにもかかわらず、得られたReward r は0(効果がなかった)ということです。
そこで、 x1-a1 の組み合わせではActionとして a1 が選択されないよう、傾向スコアを低くする必要があります。逆に、観測されたReward r が1であるような組み合わせでは、その組み合わせに用いられたActionが実行されるように、傾向スコアを高くする必要があります。
しかし、上段のPolicy π_ea ではむしろ逆の傾向でした。そこで、上段のPolicy π_ea は採用せず、別のPolicy π_eb に置き換えてみます。これにより、傾向スコアは以下のように変化しました。
・x1-Act1(Reward r = 0):0.3
・x2-Act2(Reward r = 1):0.7
・x3-Act3(Reward r = 1):0.8
Reward r が 0 になる組み合わせでは傾向スコアが低く、Reward r が 1 になる組み合わせでは傾向スコアが高くなっています。
これをもとに、上段と下段の V^(^)_IPS を算出した結果、Policy π_ea では0.42、Policy π_ea では0.92となり、期待通りとなったことがわかります。
ここまでがIPSの基本的な考え方です。
数式にすると難しそうですが、上記の計算はExcelで簡単に試すことができます。実際に計算してみると、ぐっと理解が進むため、ぜひ手計算してみることをお勧めします。
IPS Estimatorの派生として、重み上限を設定する(傾向スコアが非常に小さいときに重みが大きくなりすぎないようにする)Clipped IPS(CIPS)Estimatorや、重みを正規化するSelf-Normalized IPS(SNIPS)Estimatorも存在します。
こちらについては、冒頭に記載した勉強会資料で具体的に説明をしていますので、気になった方は是非ご覧ください。
Hybrid OPE
Model-base OPEとModel-free OPEは、以下のような違いがあります。
・Model-base OPE(Direct Method系):バイアス×、網羅性○
・Model-free OPE (IPS系):バイアス○、網羅性×
Model-base OPE で用いている Direct Methodは、学習済みの報酬推定モデル r^(^)(x,a) を通して未観測領域を疑似的に推定する手法です。観測範囲が広がるため網羅性があるものの、報酬推定モデルの学習に用いるデータはバイアスがある可能性の高いログデータです。したがって、報酬推定モデルにも何らかのバイアスが生じている懸念があります。
Model-free OPEは、バイアスの懸念がある報酬推定モデルを用いず、観測されたデータ(ログデータ)だけを用いたPolicy評価を行います。このとき、ログデータ自身のバイアスが解消されるようにIPSを用いた逆重み付けを行います。しかし、Direct Methodのように学習済みの観測用モデルを持ちるわけではないため、未観測領域の推定はできていません。
この2つの違いを整理すると、以下の図のようになります。
この課題を解決するため、Direct MethodとIPSを統合したハイブリッド手法 Hybrid OPE としてDoubly Robust Policy Estimatorが提案されています。以下に式を示します。非常に単純で、Direct MethodとIPSの式を組み合わせたものになります。
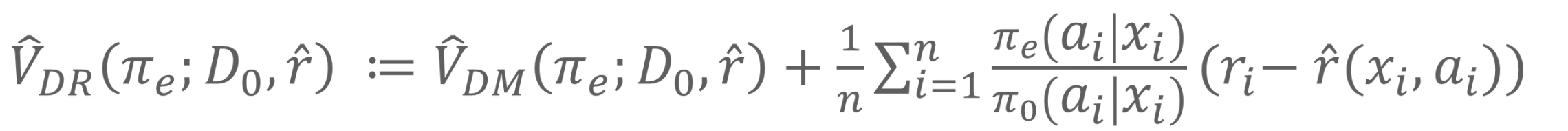
ポイントは右辺の第二項です。この項ではIPSを用いて重み付けを行っています。もともとのIPSの式では、Reward r に対して重み付けを行っていましたが、この式では r-r^(^)(x,a) に対して重み付けを行っています。
r^(^)(x,a) は Direct Methodで用いていた報酬推定モデル r^(^)(x,a) です。
報酬推定モデル r^(^)(x,a) の出力とログデータ D_0 に記録されたReward r が同一のときは、 r-r^(^)(x,a) = 0 となり第二項は無効となることを表しています。言い換えると、IPSを使わないということです。
Direct Methodは、報酬推定モデル r^(^)(x,a) がReward r を正しく推定できていることを前提としています。r-r^(^)(x,a) = 0 であれば、報酬推定モデル r^(^)(x,a) はReward r を正しく推定できているため、IPSを使わなくてもよい、という考えに基づいた設計になっています。
逆に、ログデータに記録されたReward rとDirect Methodの観測用モデルの出力一致していないときは、IPSで補正するようになっています。この補正にあたっては、Clipped IPS EstimatorやSelf-Normalized IPS Estimator と同様に、重みが想定外の数字にならないような工夫を行ったDoubly Robust with Optimistic Shrinkage (DRos) Estimatorも存在します。
上記の内容をもとに手法をまとめると以下のようになります。それぞれの特性を理解して活用するとよいでしょう。

CFMLを支える技術(オープンデータとツール)
手法を学んだあとは、実際に動かして試してみましょう。ここではそのためのツールとデータセットを紹介します。いずれもZOZOが公開しているものであり、非常に使いやすいものとなっています。
詳細はZOZOの紹介記事にお譲りし、ここでは簡単な紹介に留めさせていただきます。
Off-Policy Evaluationの基礎とZOZOTOWN大規模公開実データおよびパッケージ紹介 – ZOZO TECH BLOG
ZOZOが提供しているファッション推薦データです。ファッションのECサイトであるZOZO TOWN上で実際にレコメンドを行い、ユーザから得られたフィードバックを記録したデータセットになります。実世界上で収集したデータセットとして希少価値を持ちます。
OPEの実験を容易かつ統一された設定で行うための基盤です。バンディットアルゴリズムを代表とするPolicyの実装や、OPEを用いたオフライン評価を可能としています。今回紹介したアルゴリズムをはじめ、代表的な手法がカバーされています。
Open Bandit PipelineでOPEを用いたオフライン評価を行うときに求められるのはログデータです。そのため、新しいアルゴリズムを自分で実装したときも、出力ログをOpen Bandit Pipelineのフォーマットに合わせることでOPEを用いたオフライン評価を容易に実行できます。
Open Bandit PipelineはGoogle Colaboratoryで簡単に試すことができるようにサンプルが整備されており、すぐに試行できることもポイントの一つです。
おわりに
本記事では、次世代の意思決定技術として注目されている反実仮想機械学習(Counterfactual Machine Learning:CFML)を紹介しました。先駆者が公開してくださったサーベイ・チュートリアル資料をもとに、日本語で改めて体系的に整理することで初学者の理解の手助けとすることをねらいとしました。サーベイ・チュートリアル資料を作成くださった多くの方に御礼を申し上げます。本記事を通してCFMLに対する知見が深まれば、筆者としては喜ばしい限りです。
本記事では触れていませんが、冒頭に記載した勉強会資料では、バンディットアルゴリズムの基礎やCFMLをさらに発展させたCounterfactual XAIにも触れています。興味がありましたら、ぜひこちらもご覧ください。
さいごに、ARISE analyticsではKDDIが保有する国内最大規模のユーザデータを対象とした分析に取り組んでいます。今回紹介した内容や、その他記事で触れている弊社の取り組みに興味がございましたらぜひお声がけください。
採用 | 株式会社ARISE analytics(アライズ アナリティクス)
参考文献
執筆にあたり、以下の文献を参考にさせていただきました。
本記事でCFMLの基本的な考え方をつかんだ後は、本リストの文献を読むことでさらに理解が深まると思います。ぜひご活用ください。
特に参考にさせていただいた資料(この場を借りてお礼を申し上げます)
私のブックマーク「反実仮想機械学習」(Counterfactual Machine Learning, CFML)
KDD 2021 Counterfactual Explanations in Explainable AI: A Tutorial
KDD 2020 Tutorial on Causal Inference Meets Machine Learning
日本語の解説資料
CounterFactual Machine Learningの概要(反実仮想機械学習)
YouTubeの推薦アルゴリズムの変遷を追う〜深層学習から強化学習まで〜
DiCE: 反実仮想サンプルによる機械学習モデルの解釈/説明手法
チュートリアル・講義資料
ICML 2017 Tutorial on Real World Interactive Learning
CS7792 – Counterfactual Machine Learning
OFF POLICY EVALUATION AND LEARNING FOR INTERACTIVE SYSTEM
論文
Counterfactual Visual Explanations(ICML 2019)
Doubly Robust Policy Evaluation and Optimization(Statistical Science 2014)
CoCoX: Generating Conceptual and Counterfactual Explanations via Fault-Lines(AAAI 2020)
GNNExplainer: Generating Explanations for Graph Neural Networks(NeurIPS 2019)
Off-Policy Evaluation Using Information Borrowing and Context-Based Switching(arXiv preprint 2021 )
A Generalization of Sampling Without Replacement from a Finite Universe(JASA 1952)
Learning from Logged Implicit Exploration Data(arXiv preprint 2010)
Doubly Robust Policy Evaluation and Learning(ICML 2011)
The Self-Normalized Estimator for Counterfactual Learning(NeurIPS 2015)
Doubly robust off-policy evaluation with shrinkage(PMLR 2020)
その他資料
Doubly Robust Off-Policy Evaluation with Shrinkage
Artwork personalization at Netflix
コード、ツール
Open Bandit Pipeline: a research framework for off-policy evaluation and learning
