導入
レコメンドエンジン連載の第2回目です。
前回の「レコメンドって何?」はこちらを御覧ください。
Analytics Delivery Division Initiative Center機械学習担当の下野です。
Initiative Centerでは最新技術を用いて、分析の手法や環境を業務適用可能な品質で実現する活動しています。
SparkクラスタをKubernetes上に構築し、分析者はボタン1つで高速に自分専用の分析環境を立ち上げられるソリューションを開発しています。
KubernetesはEKSを使用しており、TerraformによりInfrastructure as Codeを実現しています。
インフラから機械学習までフルスタックな開発業務を行っています。
今回はC++でビルドされたネイティブコードを使用したモデル(ライブラリ)を用いてPySparkで分散推論する方法についてお話します。レコメンドで大量のデータを扱う際のお話しになるため、第1回からより技術的な内容になっています。
- 背景と課題
- PySparkの分散処理における落とし穴
- PySparkによる分散推論方法
- 分散推論を行うため調整すべきSparkの設定値
背景と課題
ECサイトのお客様に「レコメンドエンジン導入」支援させていただいた時の話です。
大きく2つの課題を抱えており、既存導入パッケージのレコメンドエンジンでは対応が難しくなっていました。
- 数千万から数億件の大規模な商品数
- 商品の入れ替わりが激しく、大半の商品がコールドスタート状態
これらの課題に対処するため過去のARISEアセットを高度化する形でカスタムレコメンドエンジンを適用することになりました。
コールドスタート(※第1回参照)については「商品タイトルと説明文」を用いて自然言語処理を行い、商品を数百次元のベクトル空間に埋め込むことで対処しました。
埋め込まれたベクトル(分散表現)のCosine距離が近い商品をレコメンドすることで、似ている商品をレコメンドする手法です。ログデータを使わず、商品自体を解釈して類似商品を推薦するコンテンツベースレコメンドという手法です。
自然言語処理にはFacebookが開発したfastTextを採用しました。第1回で紹介したWord2Vec系のモデルです。
PySparkの分散処理における落とし穴
fastTextですが大元のコードはC++で書かれています。
SWIGによりPythonのインタフェースを生成し、PythonからC++でビルドされたネイティブコードを呼び出しています。
推論対象の商品が数億件に上るため、PySparkのUDFを用いて分散推論させることにしました。
ここで落とし穴にハマります。
SparkではDriverで実行コードをシリアライズしてExecutorへ配布します。
Executorはコードをデシリアライズして実際に分散処理を実行します。
この際PySparkではpickleやcloudpickleを使用してシリアライズを行います。
ソースコードを確認するといくつかシリアライザーが用意されていることを確認できます。
PySparkを使用した分散推論はだいたいこのようになるのではないでしょうか。
import fasttext
import pyspark.sql.functions as F
import pyspark.sql.types as T
from pyspark.sql import SparkSession
spark = SparkSession.builder.上記のコードはsc.broadcast(model)でエラーが発生します。
PicklingError: Could not serialize broadcast: TypeError: cannot pickle 'fasttext_pybind.fasttext' object
broadcastせずUDF内で直接modelを使用しても、上記のエラーメッセージのbroadcastがobjectに変わっただけの同じエラーが発生します。
fastTextはC++でビルドされたネイティブコードを含むため、(cloud) pickleでシリアライズできないことが原因です。
C++でコア部分が書かれ、Pythonインタフェースが用意されているライブラリは機械学習では少なくないと思います。
そこで、このようなライブラリを用いてPySparkで分散推論する方法をお話します。ライブラリ側でsaveメソッドが用意され、独自ファイル形式で保存されるモデルを使用して分散推論するケースでお役に立てると思います。
PySparkによる分散推論方法
前節ではfastTextがpickleでシリアライズできないため、PySparkのUDFで使用できないことを述べました。
従ってPySpark上で分散推論を行うためにはpickleせずにExecutorへモデルを配布する必要があります。
配布方法は主に2通りあります。
- オブジェクトストレージ (S3, GCS等) を用いる
- SparkのメソッドSparkContext.addFileを用いる
分散推論方法を簡単にまとめると次の通りです。
- fastTextのsave_modelメソッドを使用してモデルファイルを保存する
- オブジェクトストレージかSparkContextにモデルファイルをアップロードする
- UDF内でオブジェクトストレージからモデルをダウンロード&読み込みして推論する
重要なことはモデルをファイルとして保存しておき、UDF内で各Executorがモデルファイルを読み込むことで、シリアライズする必要をなくしている点です。
fastTextに限らずpickleでシリアライズできないモデルオブジェクトを用いて分散推論が可能になります。
fastTextのモデルをs3へ配置して分散推論するケースを例に、具体的な実装を見ていきましょう。
実装
分散推論のため3つの機能を作成します。
- s3ダウンロード関数
- シングルトンクラス
- fastText推論クラス
シングルトンクラスについては後述します。
3つの機能の実装
s3ダウンロード関数を作成します。
# s3.py
import os
from urllib.parse import urlparse
def divide_s3_bucket_path(s3_path)シングルトンクラスを作成します。
# singleton.py
class Singleton(type):
_instances = {}
def __call__(cls, *args, **kwargs):
if cls not in cls._instances:
cls._instances[cls] = (
super(Singleton, cls).__call__(*args, **kwargs)
)
return cls._instances[cls]
推論用クラスを作成します。
# fasttext_estimator.py
from s3 import download_from_s3
from singleton import Singleton
# シングルトンクラスとして実装する
class FastTextSentenceEstimator(main実行部分を作成します。
# main.py
import pyspark.sql.functions as F
import pyspark.sql.types as T
from pyspark.sql import SparkSession
from fasttext_estimator import FastTextSentenceEstimator
spark = SparkSession.builder.分散推論部の処理フロー
main実行部分のpredict_udfが実行されます。ここにC++ネイティブコードは含まれていないのでpickleエラーは発生しません。
- ドライバでシリアライズされ配布されたpredict_udfの内容を、各Executorはデシリアライズし実行します
- タスク内でFastTextSentenceEstimator.predictメソッドが実行され、FastTextSentenceEstimatorをインスタンス化します
- FastTextSentenceEstimatorがインスタンス化される際に__init__メソッド内でs3からモデルファイルをダウンロードし、モデルを読み込んでFastTextSentenceEstimator.modelにセットします
- fastTextモデルのget_sentence_vectorメソッドにより、文章の分散表現を得ます
- 同じタスク内の2レコード目以降の処理はシングルトンパターンにより、2で生成されたFastTextSentenceEstimatorが使用されます(モデルダウンロードと読み込みは発生しません)
- タスク数分2-5を繰り返します
このようにC++ネイティブコードをpickle化する工程を避けることと、シングルトンパターンにより高速にPySpark上で分散推論を実現します。
シングルトンクラスについて
これまで触れられなかったシングルトンクラスの役割について少しお話します。
シングルトンとはデザインパターンの1つで、その(クラスの)インスタンスが1つしか生成されないものを指します。
クラスをインスタンス化すると都度つどメモリ上の別アドレスに新しいインスタンスが生成されます。
class Dummy:
def __init__(self):
pass
dummy1 = Dummy()
dummy2 = Dummy()
# メモリ上の別アドレスに生成されるためAssertionErrしかしシングルトンパターンを用いると、すでにそのクラスのインスタンスが生成されている場合、その生成済インスタンスを返します。
class DummySingleton(metaclass=SparkのUDFで分散推論するにあたりシングルトンは、UDF処理を行うタスク内でモデル読み込みが一度で済むため処理が高速化できるという大きなメリットがあります。
通常UDFはDataFrameのレコード単位で処理を行うため、シングルトンを使用しない場合レコード数分モデル読み込みを行います。
シングルトンを使用すれば、Sparkのタスク数分だけのモデルを読み込みすれば良くなるので、処理時間の大幅短縮が見込めます。
Pandas UDFにおいてもシングルトンは有効です。
Pandas UDFでは、spark.sql.execution.arrow.maxRecordsPerBatchで指定されたレコード数(デフォルトは10000)ごとにバッチ処理を行います。
つまり1つのタスクで処理する行数がこの値を超える場合、1タスク内で複数回モデルダウンロードと読み込みをします。
シングルトンを使用すれば、Pandas UDFにおいても1タスク内で一度のモデル読み込みで済ませることができます。
シングルトンによるノーマルUDF実行時間の違いを、以下の実験条件で比較しました。
モデルの読み込み時に5秒かかる処理を想定しています。
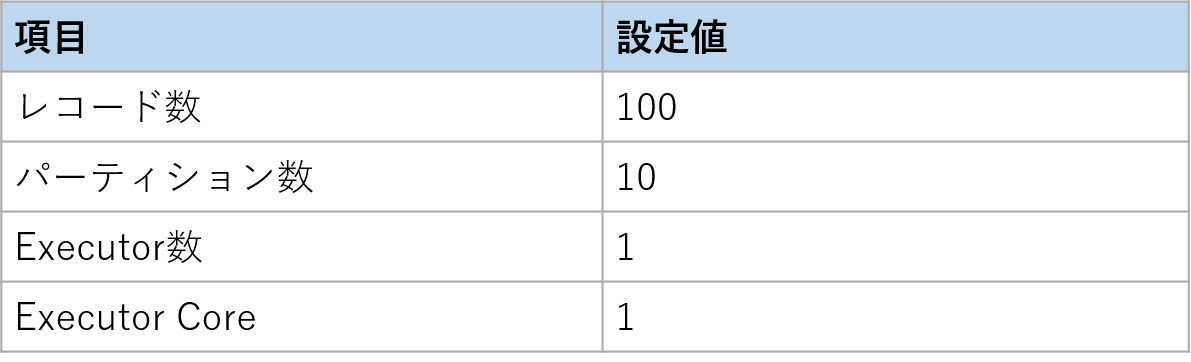
画像のDurationカラムに注目してください。
通常はレコード毎にモデル読み込みが行われるため、1タスク(10レコード)終えるのに50秒(5秒x10レコード)以上かかっています。
シングルトンパターン適用時は、タスクの始めに一度読み込むだけなので1タスク5秒程度で処理が完了しています。
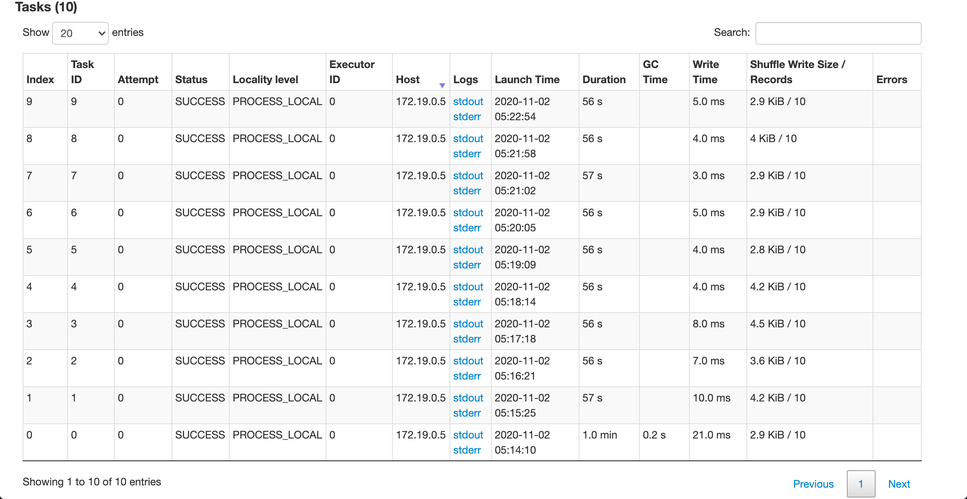
通常時のSpark Task実行時間
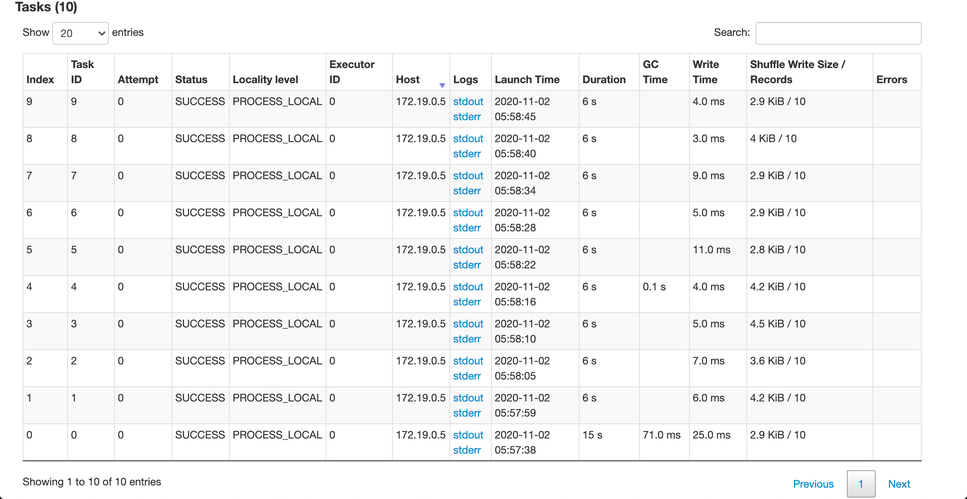
シングルトンパターン適用時のSpark Task実行時間
オブジェクトストレージを用いない簡易な実装
ここまでオブジェクトストレージ(s3)を用いた実装を紹介しました。
fastTextのようにモデルがシングルファイルで保存される場合にはSparkContext.addFileでモデルファイルをアップロードする方法が簡単です。
ExecutorからはSparkFiles.getでファイル取得します。
こちらの方法も簡単にサンプルコードを記載します。
重要な点はmain実行部分で分散推論のUDFが実行される前にaddFileをする必要があることです。
# main.py
# ローカルにあるモデルファイルをアップロードする
spark.sparkContext.addFile('/推論クラスの方はSparkFiles.getでaddFileされたファイルを使用すれば良いです。
# fasttext_estimator.py
from pyspark import SparkFiles
...
class FastTextSentenceEstimator(オブジェクトストレージとaddFileの使い分けですが、個人的には基本的にaddFileを使用が簡単で良いと考えています。
モデルファイルがディレクトリ構造で保存されるケース等、addFileで対応できないケースの際にオブジェクトストレージからダウンロードする方法を使用する使い分けに私はしています。
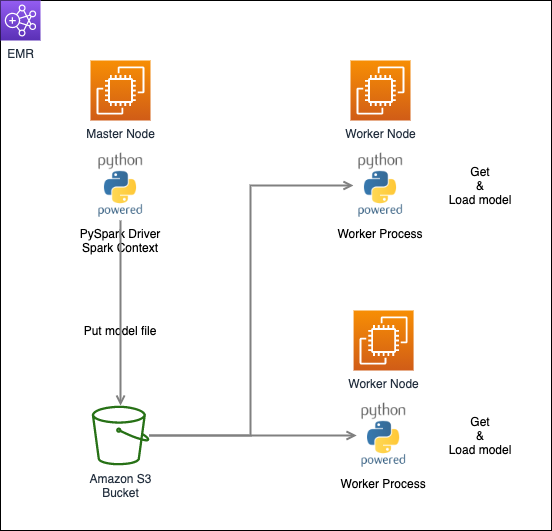
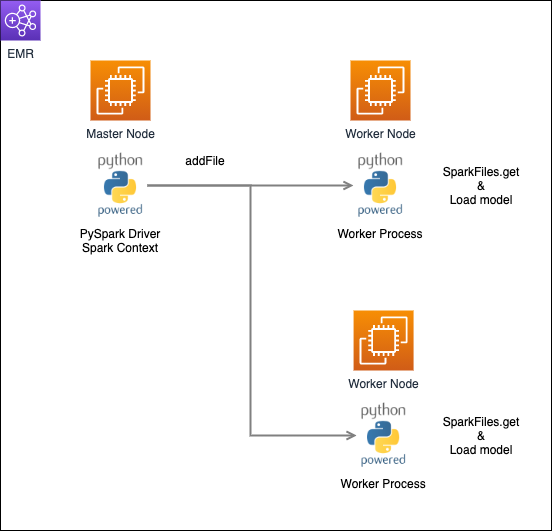
モデル配布3手法の概念図
ここまで紹介してきた3つのExecutorへのモデル配布手法を簡単な概念図にまとめると以下のようになります。
- broadcastでシリアライズして配布する方法 (今回のケースでは例外が発生)
- S3 (オブジェクトストレージ) 経由で配布する方法
- addFileで配布する方法 (今回のケースでは例外が発生)
1はPythonオブジェクトのシリアライズを行うのに対し、2, 3の手法はモデルファイルを直接Executorへ配布しています。
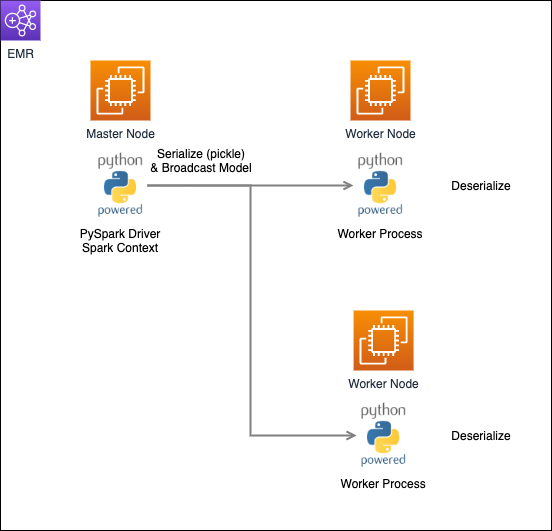
broadcastでシリアライズして配布
S3経由で配布
addFileで配布
分散推論を行うため調整すべきSparkの設定値
今回のようにSpark外のライブラリを使用して分散推論する際、UDFを安定して稼働させるためにはSparkの設定値を調整する必要があります。
ライブラリのモデルが使用するCPUやメモリは、Sparkが管理するExecutor JVMの管理外のリソースを使用するためです。
ベストプラクティス等に従ってExecutorのCPUやメモリ割り当てた状態では、モデルが使用するリソースを考慮していないため、タスクの並列度が高すぎてリソース不足により失敗することがあります。
Sparkの設定値を適切に与えて分散推論UDF実行時に、OOM Killerにより実行が失敗するやロードアベレージの著しい上昇の発生を抑えることができます。
分散推論手法を考えていた当時は、OOM Killerのようにメモリ不足によりUDF実行が失敗していたことが多々あり、原因特定に苦労しました。
リソース不足によるUDFの失敗を避けるため行うことです。
- Executorインスタンス数とCPU割り当てを減らしタスク並列度を下げる
- Executorインスタンス数調整のため、メモリ設定値を調整する
- モデルが使用するメモリ確保のためmemoryOverheadを多く確保する
上記を行うため必要なSpark設定値です。
公式説明はこちらを御覧ください。

上記の値に決まった正解はないのですが、適切な値の探り方を紹介します。
- spark.executor.coresを1に設定してタスク並列度を下げる
- 1 Workerノードで1 Executorしか起動しないようspark.executor.memoryとspark.executor.memoryOverheadを極振りする
- spark.executor.memoryとspark.executor.memoryOverheadを半分にして1 Workerノードで2 Executor起動するようにする
- 3を繰り返し1 Workerノードで起動できるExecutor数を最大化する(繰り返すうちメモリエラーでUDFが失敗する)
- spark.executor.coresを増やし、spark.executor.memoryとspark.executor.memoryOverheadを減らし実行速度が最適となるタスク並列度を求める
メモリを大きく確保してExecutorのインスタンス数を抑えつつ少しずつ調整します。
まとめ
長くなりましたが今回の簡単なまとめです。
- ネイティブコードはPythonのpickleでシリアライズできないため、通常の方法だとUDFで使用できない
- オブジェクトストレージやSparkContext.addFileを使用することで、pickleする過程を避けSparkで分散推論が可能になる
- 分散推論のUDFを安定させるにはSparkの設定値spark.executor.{cores|memory|memoryOverhead}を調整すると良い
参考
- TensorFlow Kerasでも一部pickleによるシリアライズが推奨されておらず、今回の手法が有効です
- 本家fastTextにもSparkで今回の問題が解決策となるissueが上がってました
- Sparkをバックエンドに使用できるApache BeamのGCPマネージドサービスDataflowのexampleにも、TensorFlowとシングルトンパターンで分散推論するものがありました
